RAG¶
约 1196 个字 11 张图片 预计阅读时间 6 分钟
- 代码 --> RAG_from_scratch 这个仓库的代码使用 langchain 作为框架
R-Retrieve 检索
A-Augment 增强
G-Generate 生成
RAG 用于解决以下问题:
- 幻觉 ( 生成不存在的信息 )
- 数据时效性弱
- 大模型上下文窗口有限,不过现在模型都在朝无限上下文靠拢
- ....
概览: 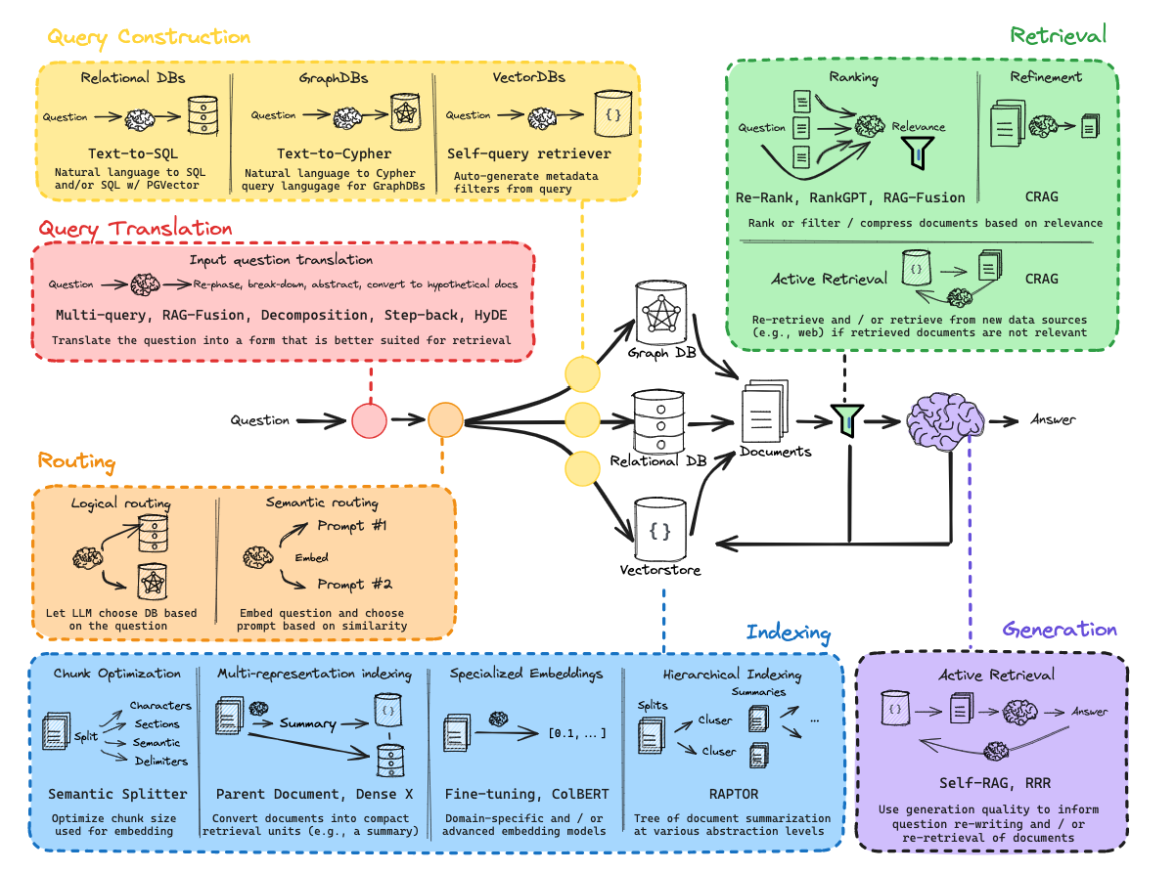
最简单的 RAG_demo ¶
- 读取用户输入的 question,
- 查询相关文档
- 将这些文档作为上下文
- 生成 answer
Query translation¶
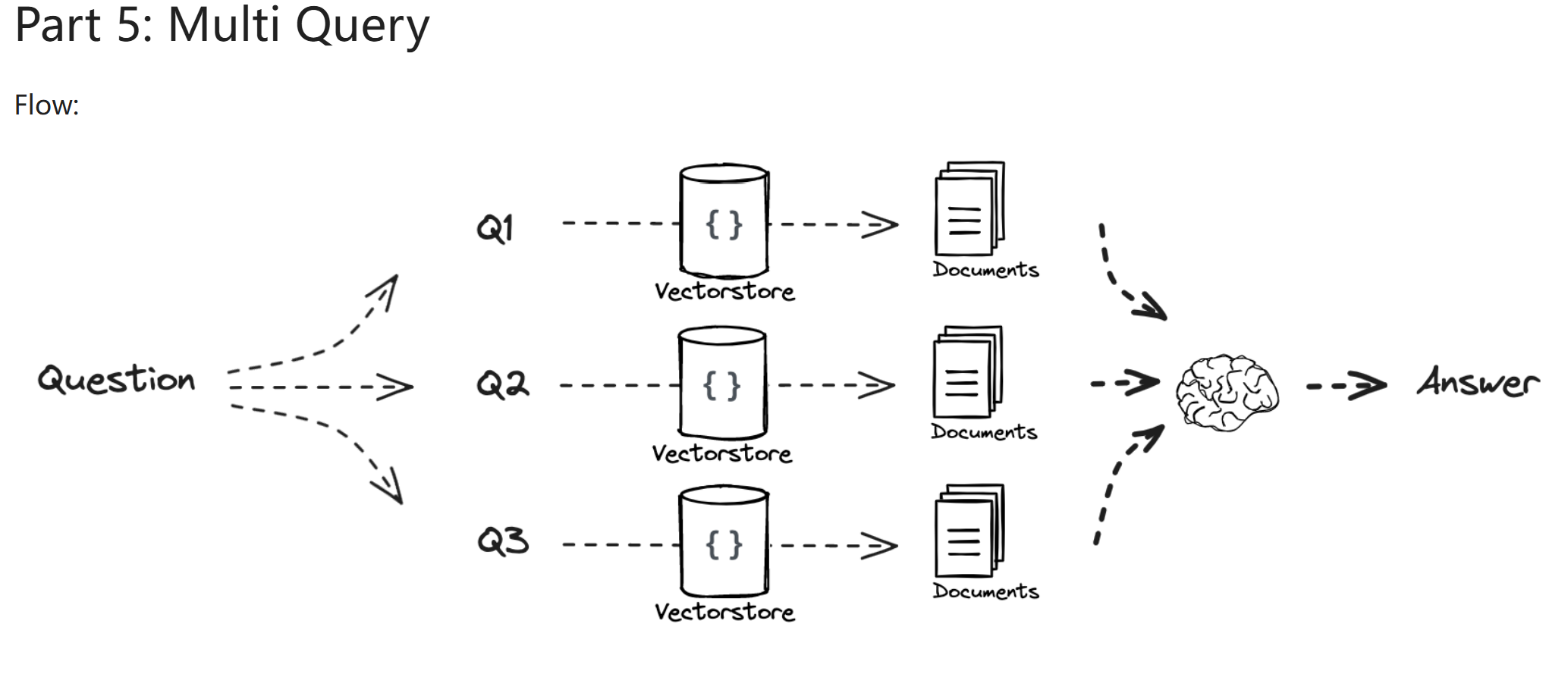
mutiquery¶
- 读取用户输入的 question
- 生成相关问题
- 通过相关问题查找文档
- 整合文档作为上下文
- 生成 answer
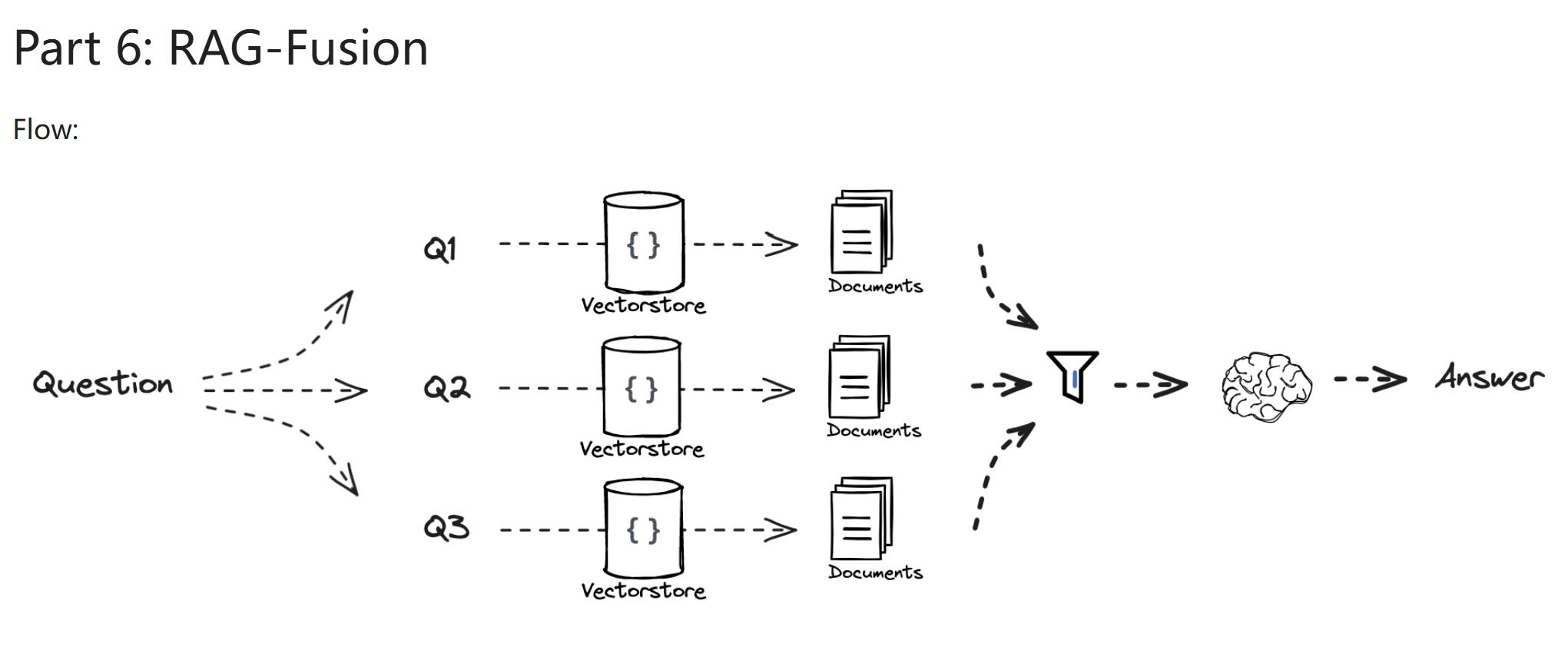
RAG-Fusion¶
- 读取输入的 question
- 生成相关问题
- 通过相关问题查找文档
- 用某种机制对文档进行过滤,找到 " 高质量 " 文档作为上下文
- 生成 answer
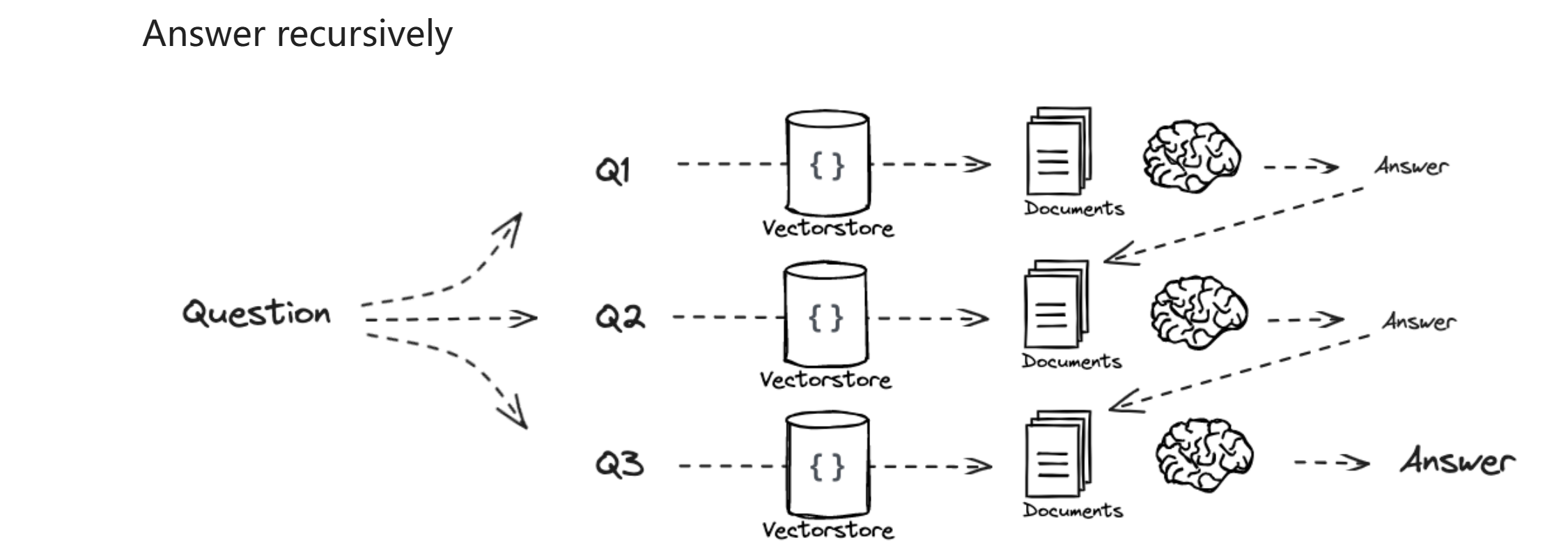
Decomposition¶
- answer recursively 把问题分成几个子问题,回答子问题 2 时,上下文分为两部分,第一部分是子问题 1 和答案 1,第二部分是子问题 2retrieve 的结果,递归进行最后生成答案 有点 cot 的感觉
- answer individually 跟 recursively 的不同就是把所有子问题和对应解答打包作为上下文回答 origin question
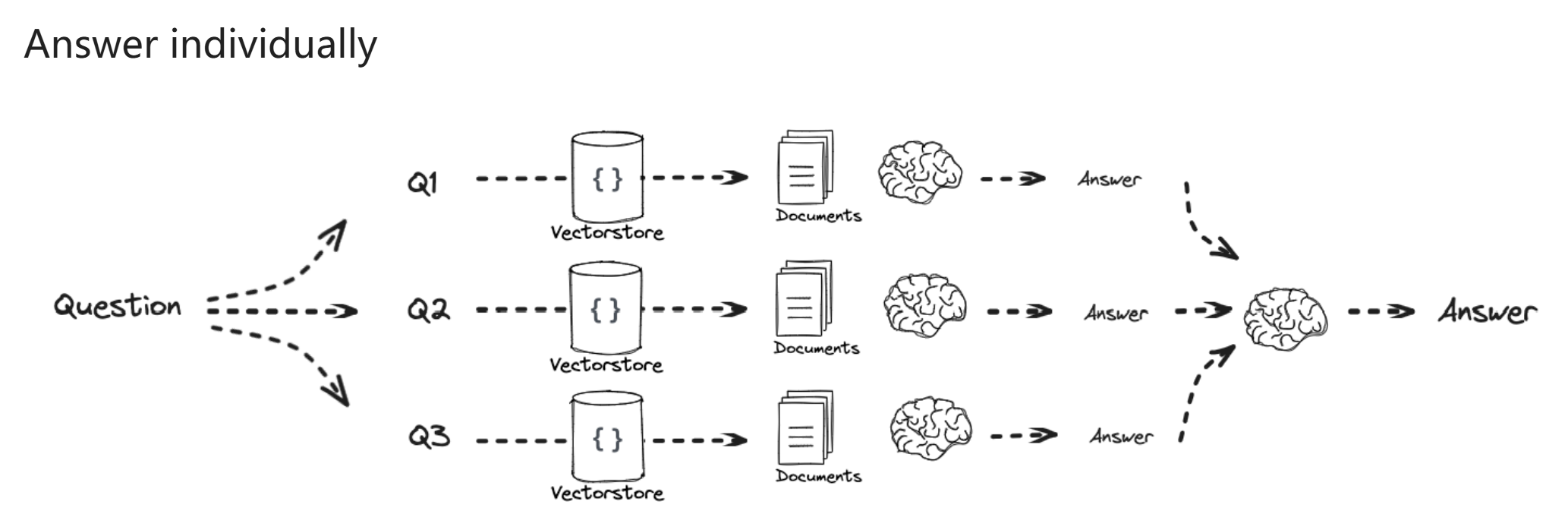
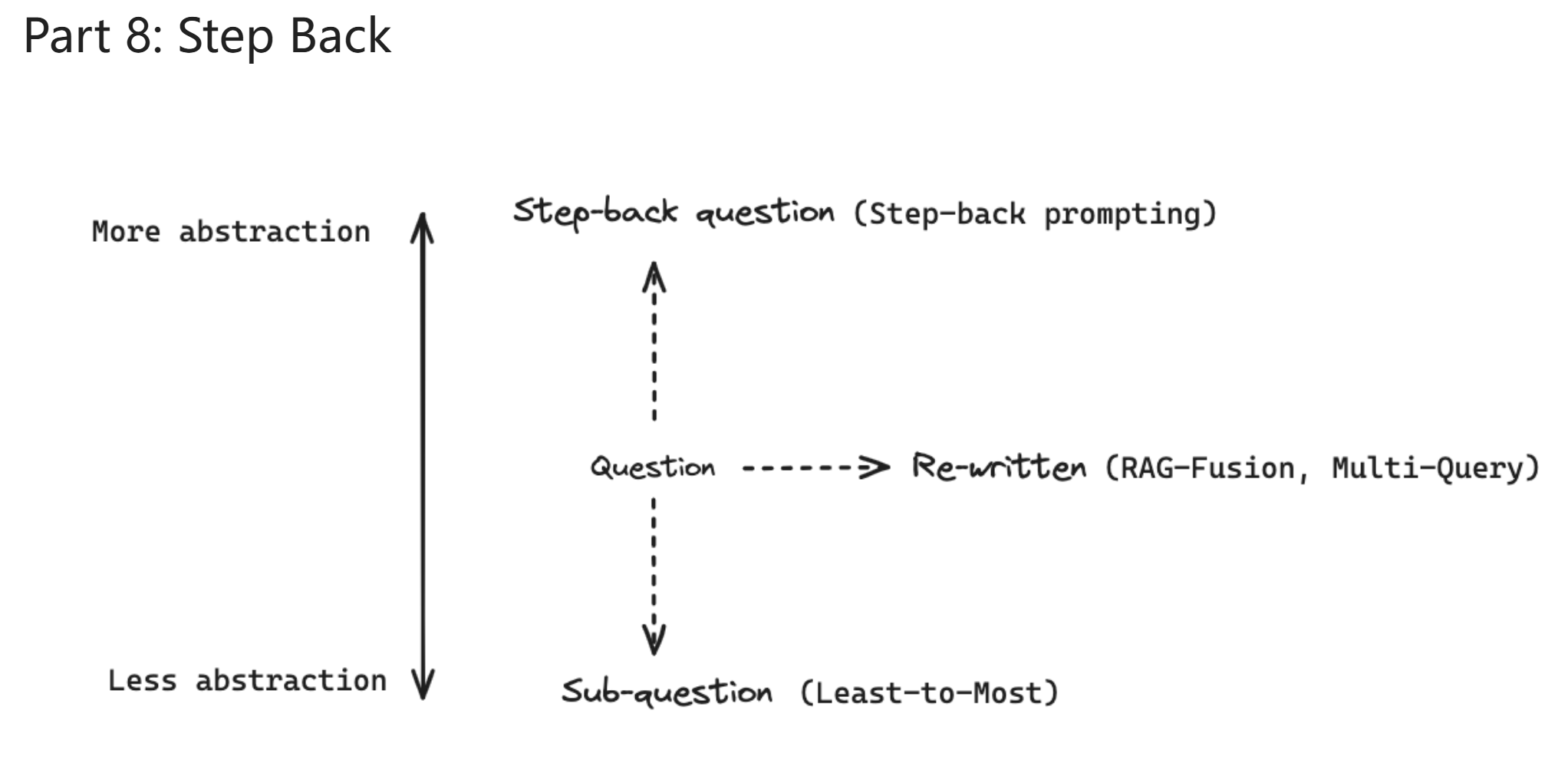
step back¶
- 读取输入的 question
- 把问题退化为一个更容易给出精确回答的问题
- 把对退化后问题的回答和 retrieve 的结果作为上下文
- 生成 answer
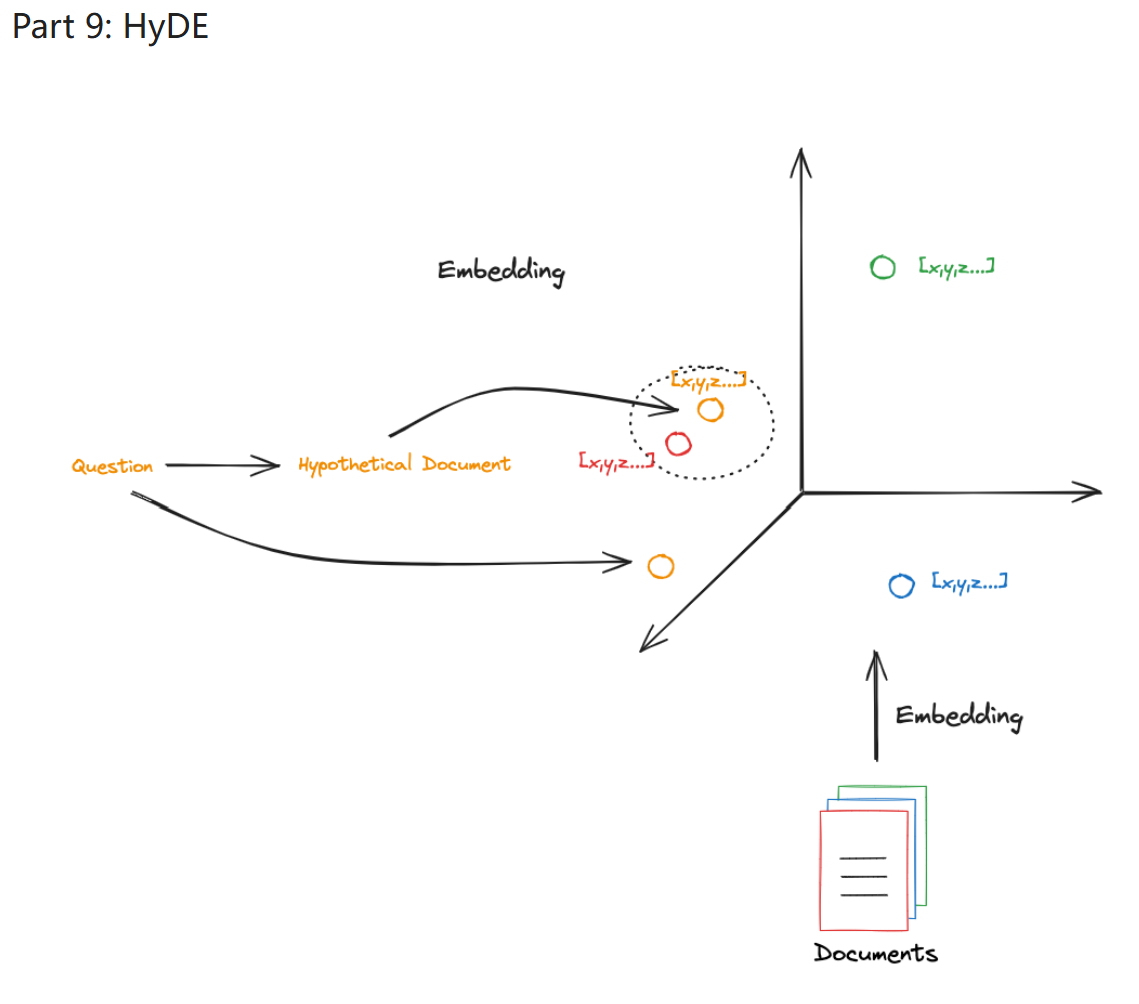
HyDE¶
- 读取输入的 question
- 通过 question 生成一个科学性文档
- 通过这个文档进行 retrieve 得到上下文
- 生成 answer
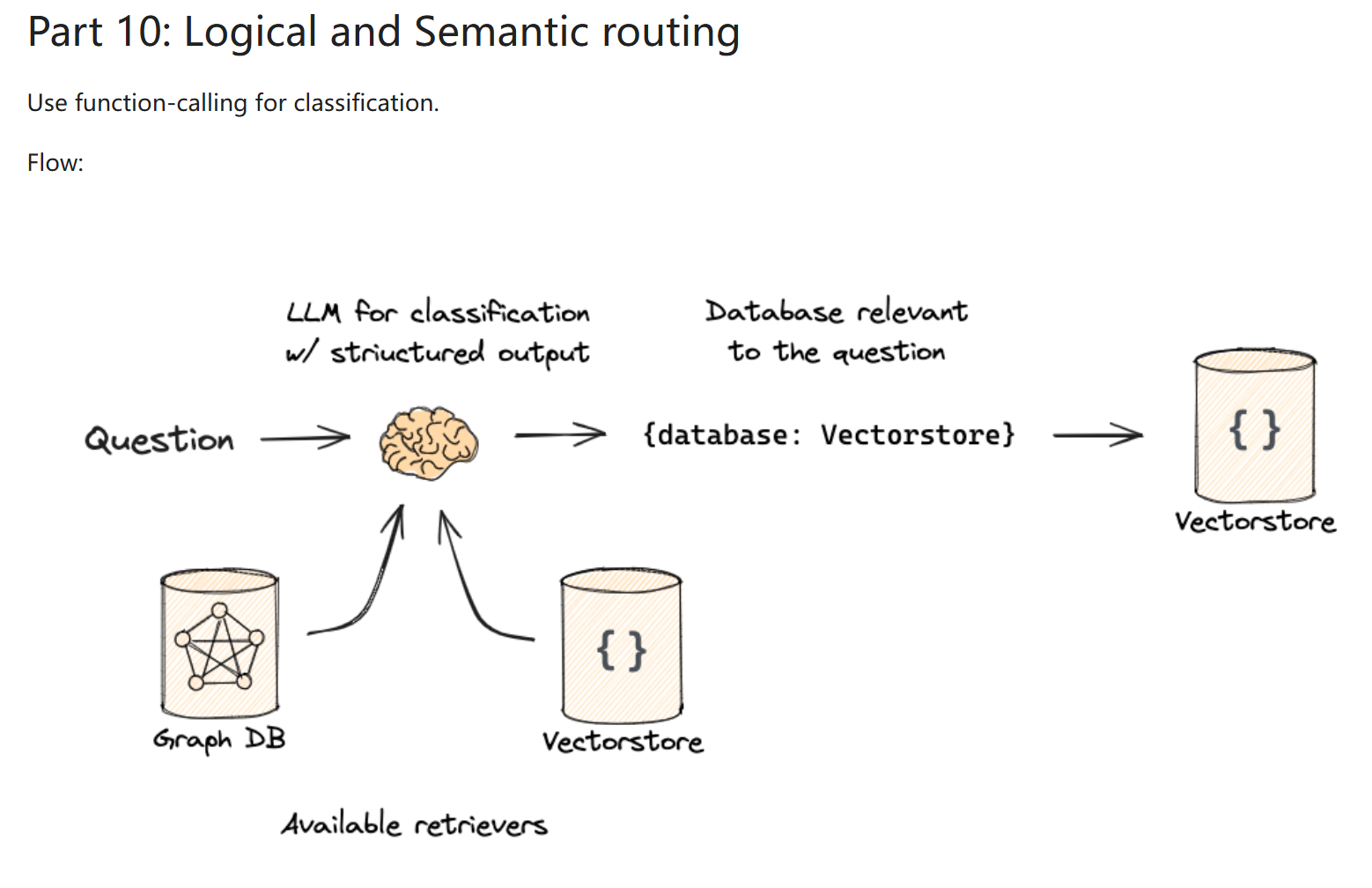
Routing¶
logical routing¶
- 读取用户输入的 query
- 分析 query 的逻辑结构
- 根据逻辑规则选择合适的数据源
- 从选定的数据源中检索相关文档
- 使用检索到的文档生成 answer
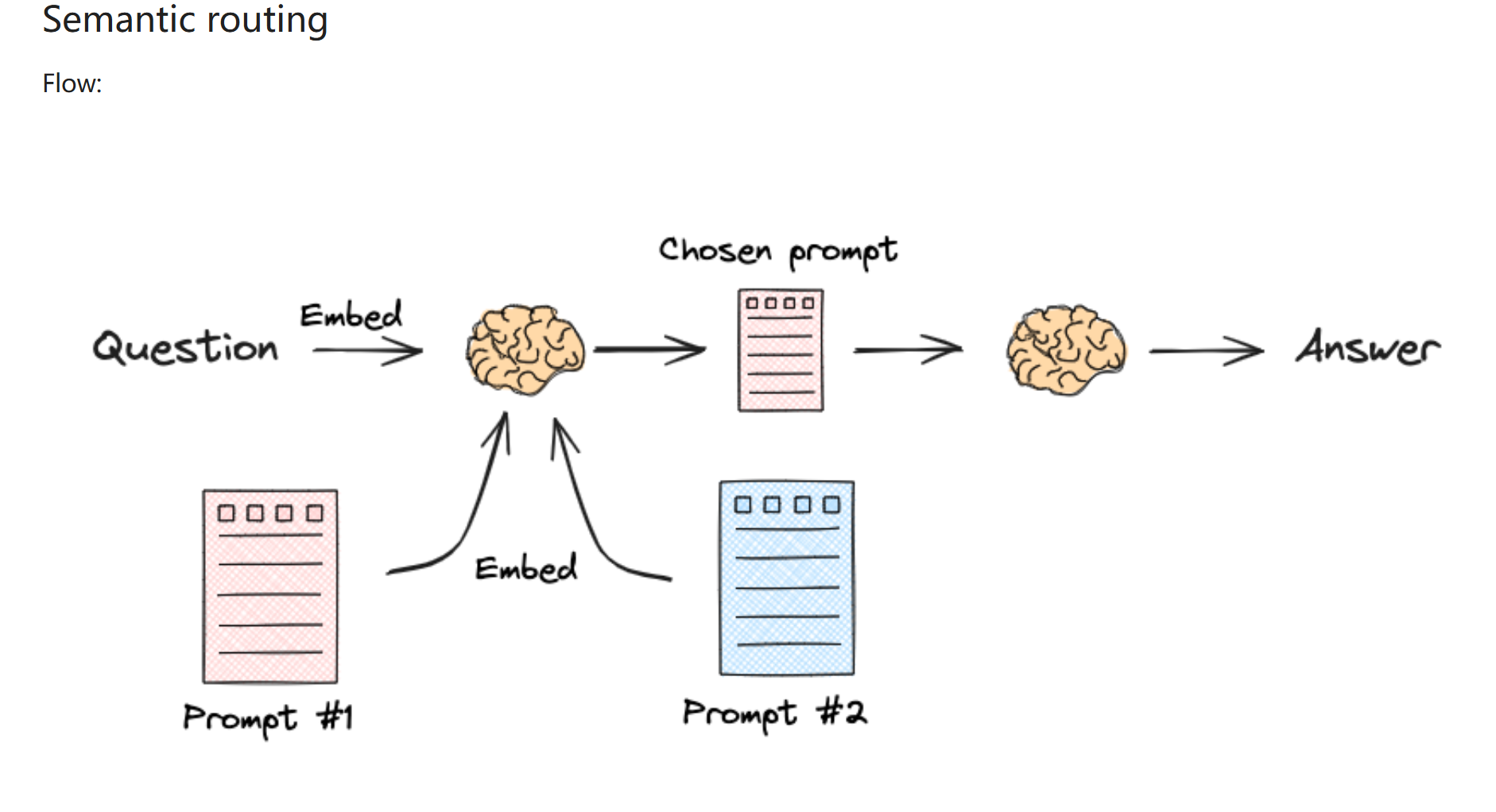
semantic routing¶
- 读取用户输入的 query
- 将 query 转换为语义向量
- 根据语义相似度选择合适的数据源
- 从选定的数据源中检索相关文档
- 使用检索到的文档生成 answer
Query Construction¶
Query structuring for metadata filters¶
- 读取用户输入的 query
- 分析 query 中的关键字和意图
- 将 query 转换为结构化格式,适用于元数据过滤
- 应用元数据过滤器筛选相关文档
- 使用筛选后的文档生成 answer

Indexing¶
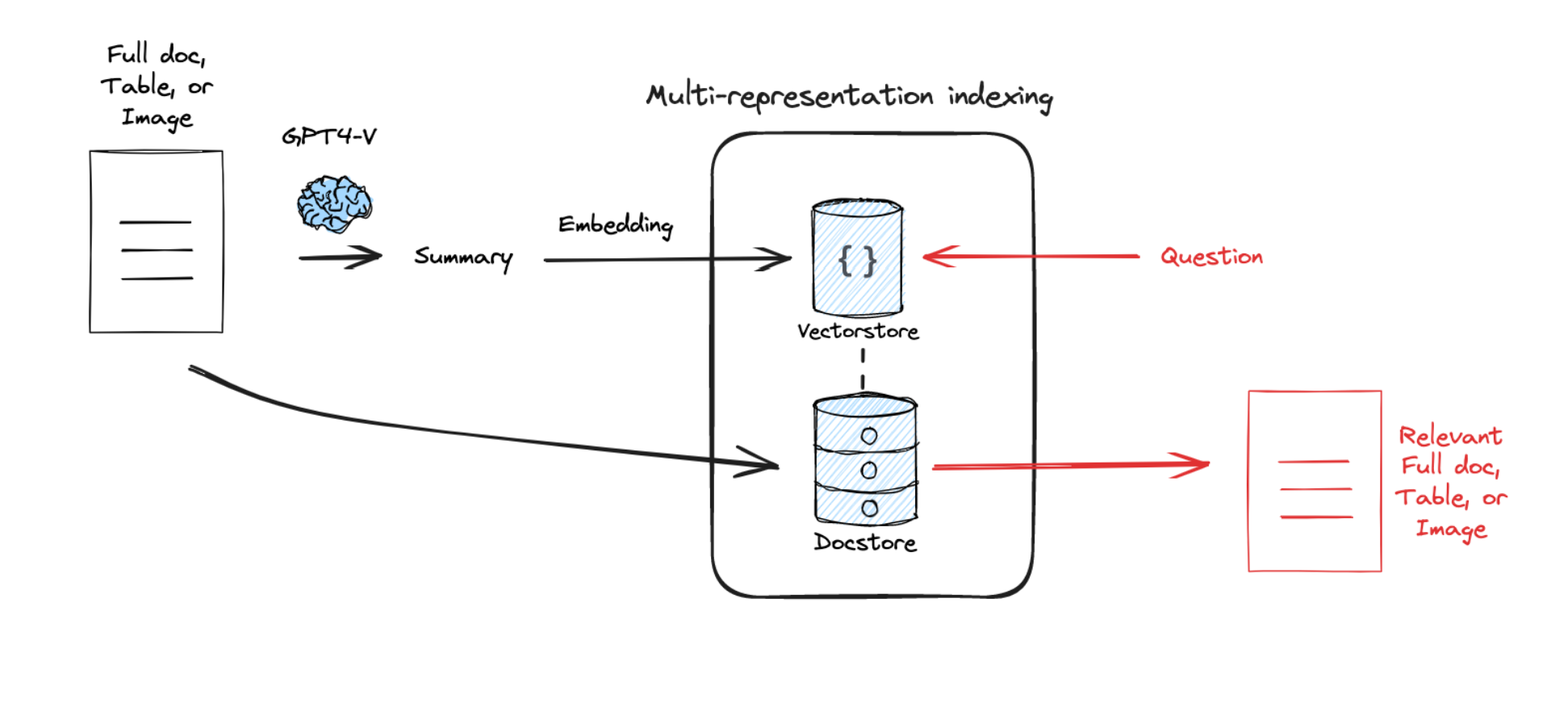
Multi-representation Indexing¶
- 读取输入的文档
- 为每个文档生成多种表示形式: - 生成摘要向量 - 生成原文向量 - 生成结构化信息
- 分别存储这些表示: - 摘要存入向量数据库 - 原文存入文档存储 - 用唯一 ID 关联不同表示
- 检索时: - 先通过摘要快速定位相关文档 - 再通过 ID 获取完整原文 - 最后生成 answer
RAPTOR¶
- 读取用户查询
-
查询优化: - 分析原始查询 - 生成多个优化版本的查询 - 选择最佳查询版本
-
检索增强: - 使用优化后的查询进行检索 - 对检索结果进行相关性排序 - 过滤低质量结果
-
提示词重写: - 根据检索结果动态调整提示词 - 加入上下文信息 - 优化提示词结构
-
迭代优化: - 评估生成结果质量 - 根据反馈调整检索策略 - 持续改进提示词模板
ColBERT¶
- 读取输入的文档和查询
-
生成 token 级别的向量表示: - 为文档中每个 token 生成向量 - 为查询中每个 token 生成向量
-
进行延迟交互: - 在检索时计算查询和文档 token 的相似度 - 通过最大相似度计算文档得分
-
检索和排序: - 使用向量数据库快速检索相关文档 - 根据相似度得分排序文档
-
生成 answer: - 使用检索到的文档作为上下文 - 生成最终的回答
Retrieval¶
Re-ranking ( 在 RAG-Fusion 中提到过一遍 '_') ¶
- 初步检索相关文档
- 使用高级模型对初步结果进行重新排序
- 根据新的排序选择最相关的文档
- 使用这些文档生成 answer
CRAG (Corrective Retrieval-Augmented Generation)¶
- 读取用户输入的 query
- 初步检索相关文档
- 生成初步 answer
- 根据初步 answer 进行检索修正
- 使用修正后的文档生成更准确的 answer
Generation¶
self-RAG¶
- 读取用户输入的 query
- 自我检索相关文档
- 自我生成初步 answer
- 评估初步 answer 的质量
- 根据评估结果进行自我调整和优化
impact of long context¶
- 读取用户输入的 query
- 检索长上下文文档
- 分析长上下文对生成 answer 的影响
- 优化长上下文的使用策略
- 生成更具上下文相关性的 answer