速成 C++
约 3837 个字 871 行代码 1 张图片 预计阅读时间 30 分钟
- 记载了前九章内容的笔记并摘出了源码
- 相关资源
- 食用建议
- 速读原文 -> 写关键词 -> 主动回忆 -> 整合笔记
0 开始学习 C++ ¶
0.1 注释 ¶
0.2 #include指令 ¶
- C++
- 语言核心
- 标准库
#include把不在语言核心的名称包含到当前文件中,是预处理指令的一种,本质上会把其后的文件内容复制到当前文件指定的位置<iostream>表示对顺序或流输入 / 输出的支持
0.3 main 函数 ¶
- 函数是一段具有名称的程序片段
- C++ 程序有且仅有一个
main函数 - main 函数要返回一个整数类型的值作为结果,零表示成功,其他任意意味着程序运行有问题
int是语言核心内用于表示整数的名称
0.4 花括号 ¶
- C++ 中,编译器把出现在花括号之间的所有内容当作一个单元处理,这个单元就是栈帧
0.5 使用标准库进行输出 ¶
- 名字空间是一个相关名称的集合
std::cout:名称之前的std::表明cout是名为 std 的名字空间的一部分std::cout是标准输出流,标准输出流是 C++ 实现用来进行普通的程序输出的工具。在窗口操作系统环境下的一个典型的 C++ 实现中,在程序运行时,系统环境会把程序和一个窗口联系起来,std::cout指示了这个窗口std::endl表示一个语句行的结束。这意味着如果后续还有输出,则会在新一行中开始
0.6 返回语句 ¶
- 如
return 0; - 返回值的类型必须和函数声明的返回类型一致
- 接受 main 的返回值的程序是 C++ 实现本身 ( 有点抽象 ...)
0.7 深入观察 ¶
- 表达式指示 C++ 编译器对某些事物进行运算。
- 运算会产生一个结果, 并且可能有副作用( 类似 python 中的纯函数和非纯函数),副作用不作为表达式额直接结果,但是会影响程序或系统环境的状态。如果在表达式后紧跟分号,表示让系统丢掉该表达式的结果,表示我们只对该表达式的副作用关心。
- 例如
3 + 4这个运算的结果是 7 但是没有副作用。 - 表达式包含运算符和操作数
- 每个操作数都具有类型,
std::cout的类型就是std::ostream - C++
- 内建模型,如
int - 语言模型之外的其他类型
- 内建模型,如
std::endl本质上是一个控制器- 控制器的关键性质:把控制器写到流中,我们就可以控制这个流。
- 就
std::endl而言,我们所作的动作是结束当前的输出行 std::cout << "Hello, World!" << std::endl;会产生一个类型为std::ostream的std::cout作为其结果(这也是为什么可以进行链式调用的原因) ,作为副作用,它会将 Hello, World! 写入标准输出中并结束当前输出行。- 作用域是用来避免名称冲突的手段
- 名字空间作用域:
std::cout是一种限定名称,其中::是作用域运算符 - 花括号是另一种作用域
0.8 小结 ¶
- C++ 程序通常具有自由风格
- 自由风格:防止相邻名称混在一起时必须使用空白的编码风格
- 三个不能具有自由风格的例外 ( 不可以跨行 )
- 字符串直接量
#include名称//注释
01 开始学习 C++ ¶
1.1 输入 ¶
C++
#include <iostream>
#include <string>
int main()
{
std::cout << "Please enter your first name: ";
std::string name;
std::cin >> name;
std::cout << "Hello, " + name + "!" << std::endl;
return 0;
}
- 变量:具有名称的对象。有的对象可能没有名称。
- 对象是计算机中一段具有类型的内存空间。
- 定义变量,名称 + 类型,
std::string name定义了一个类型为std::string的变量name std::string定义在标准头<string>中,变量 name 定义在 main 函数中,表示 name 是一个 局部变量- 局部变量的生存期是大括号内
- 接口是某类型对象可实现操作的集合
- 定义一个类型为
string的具名对象 name,则表示能够对 name 做库所允许对string类型对象做的所有操作 - 其中一个操作是初始化,标准库要求每一个
string类型对象都有一个初始值,这意味着如果不显示为string类型对象指定值,则系统环境会对该对象进行隐式初始化,这样的对象就是一个不含任何字符的空串。 - 输入语句
- 就
std::cin >> name而言,>>运算符会从标准输入读入一个字符串并将其存储在 name 变量中。该表达式的结果是std::cin,这表明其也支持链式调用。 - 它会略去输入开始所碰到的空白字符(例如换行符、制表符等等
) ,之后会连续读入字符到变量 name 中,直到遇到其他空白字符或文件结束标记。
- 就
- 缓冲区 (buffer)
- 通常,输入 / 输出操作会将它的输出保存在缓冲区这样的内部数据结构中。
- 缓冲区是用来优化输出操作的,只有在必要的时候,系统才会把缓冲区的内容写入到输出装置中,从而刷新缓冲区。这样就可以把几个输出操作合并到一个单独的写操作中了。
- 缓冲区刷新
- 缓冲区满了
- 请求从标准输入中读取数据
- 明确要求刷新,如
std::flush,std::endl
1.2 为姓名装框 ¶
C++
#include <iostream>
#include <string>
int main()
{
std::cout << "Please enter your first name: ";
std::string name;
std::cin >> name;
const std::string greeting = "Hello, " + name + "!";
const std::string spaces(greeting.size(), ' ');
const std::string second = "* " + spaces + " *";
const std::string first(second.size(), '*');
std::cout << std::endl;
std::cout << first << std::endl;
std::cout << second << std::endl;
std::cout << "* " + greeting + " *" << std::endl;
std::cout << second << std::endl;
std::cout << first << std::endl;
return 0;
}
- C++ 允许使用
+连接一个字符串和一个字符串直接量或两个字符串。例如:"Hello, " + name + "!"。 - 但
+不允许连接两个字符串直接量。如cout << "hello," + "world" << end;(error!!) - 运算符重载 : 如果一个运算符对于不同类型的操作数来说具有不同的含义,那么我们就说这个运算符被重载了,本例中
+可以用于数学计算也可以用于字符串的连接,所以+被重载了。 const: 用于表示常量的关键字,对常量定义的同时必须对其进行初始化,否则将不会再有机会对其进行初始化,因为系统环境会对string类型对象进行隐式初始化,而常量的值不允许修改。- 另外注意到
const std::string greeting = "Hello, " + name + "!",这表示对常量的初始化值不必是一个常量。(name 是变量 ) - 成员函数:
greeting.size(),string类型对象内部有一个成员 size 函数 - 字符直接量: 单引号
' '用来表示字符直接量。其所对应的内建类型为char。 - C++ 允许根据一个整数值和一个字符值来构造字符串。
- 例如
std::string stars(10, '*')定义一个包含有 10 个'*'字符的字符串 starts 。
1.3 小结 ¶
02 循环和计数 ¶
2.1 问题 ¶
C++
#include <iostream>
#include <string>
// say what standard-library names we use
using std::cin; using std::endl;
using std::cout; using std::string;
int main()
{
// ask for the person's name
cout << "Please enter your first name: ";
// read the name
string name;
cin >> name;
// build the message that we intend to write
const string greeting = "Hello, " + name + "!";
// the number of blanks surrounding the greeting
const int pad = 1;
// the number of rows and columns to write
const int rows = pad * 2 + 3;
const string::size_type cols = greeting.size() + pad * 2 + 2;
// write a blank line to separate the output from the input
cout << endl;
// write `rows' rows of output
// invariant: we have written `r' rows so far
for (int r = 0; r != rows; ++r) {
string::size_type c = 0;
// invariant: we have written `c' characters so far in the current row
while (c != cols) {
// is it time to write the greeting?
if (r == pad + 1 && c == pad + 1) {
cout << greeting;
c += greeting.size();
} else {
// are we on the border?
if (r == 0 || r == rows - 1 ||
c == 0 || c == cols - 1)
cout << "*";
else
cout << " ";
++c;
}
}
cout << endl;
}
return 0;
}
2.2 程序的整体结构 ¶
2.3 输出数目未知的行 ¶
2.4 输出一行 ¶
2.5 完整的框架程序 ¶
- using 声明:
using std::cout这个声明可以实现仅一次的说明cout这个名称是来自于std这个名称空间的,从而避免重复使用std::,当然这同时隐含着 " 我们不会定义自己的cout" 这一信息 - 使用
using声明的名称与其他名称具有同样的特性,例如在大括号中使用using声明的名称其生存期自定义开始,到大括号结束。 - 短路现象:
condition1 || condition2, 如果 condition1 为真,后续不再执行condition1 && condition2, 如果 condition1 为假,后续不再执行
2.6 计数 ¶
2.7 小结 ¶
- 操作数组合方式 -- 运算符的优先级和结合性决定。
- 操作数怎样被转换为其他类型
- 操作数的运算次序
03 使用批量数据 ¶
C++
#include <iostream>
#include <string>
#include <ios>
#include <iomanip>
using std::cout; using std::string;
using std::cin; using std::endl;
using std::streamsize; using std::setprecision;
int main()
{
cout << "Please enter your first name: ";
string name;
cin >> name;
cout << "Hello, " << name << "!" << endl;
cout << "Please enter your midterm and final exam grades: ";
double midterm, final;
cin >> midterm >> final;
cout << "Enter all your homework grades, "
"followed by end-of-file: ";
int count = 0;
double sum = 0;
double x;
while (cin >> x) {
++count;
sum += x;
}
streamsize prec = cout.precision();
cout << "Your final grade is " << setprecision(3)
<< 0.2 * midterm + 0.4 * final + 0.4 * sum / count
<< setprecision(prec) << endl;
return 0;
}
3.1 计算学生成绩 ¶
- 两个以上字符串直接量仅仅被空白符分隔开,那么这些字符串直接量就会被自动连接到一起。
和
等价。
- 缺省初始化
- 对于自定义类型,例如
string,当我们在声明该类型变量的同时不进行初始化赋值操作,则该类型会自动的被隐含初始化为空字符串。 - 但是定义内置类型的局部变量时,系统并不会提供该便利。这意味着我们在定义基本类型的变量时,需要手动为其进行初始化,否则可能会导致程序出现意想不到的错误。
- 错误指:系统给这些变量分配适当的内存单元,而变量的值就有这些单元中的随机信息组成。
- 对于自定义类型,例如
setprecision- 位于头文件
<iomanip>中,用于指明输出所包含的有效位数。 - 是一个控制器,为流的后继输出设置了一个特定的有效位数
- 位于头文件
streamsize- 位于头文件
<ios>中,输入输出使用该类型表示长度
- 位于头文件
precision- cout 的成员函数,用于返回流在输出浮点数时所使用的精度。
cin >> x作为条件:- 类 istream 提供了一个转换来把 cin 转换成一个可以在条件中使用的值。
- 用 cin 作为条件等价于检测最近一次从 cin 读数据的尝试是否成功。
- 以下情况可能会失败
- 到达输入文件的末尾
- 输入和试图读取的变量不一致
- 系统在输入装置中检测到一个硬件问题
3.2 中值代替平均值 ¶
C++
#include <algorithm>
#include <iomanip>
#include <ios>
#include <iostream>
#include <string>
#include <vector>
using std::cin; using std::sort;
using std::cout; using std::streamsize;
using std::endl; using std::string;
using std::setprecision; using std::vector;
int main()
{
// ask for and read the student's name
cout << "Please enter your first name: ";
string name;
cin >> name;
cout << "Hello, " << name << "!" << endl;
// ask for and read the midterm and final grades
cout << "Please enter your midterm and final exam grades: ";
double midterm, final;
cin >> midterm >> final;
// ask for and read the homework grades
cout << "Enter all your homework grades, "
"followed by end-of-file: ";
vector<double> homework;
double x;
// invariant: `homework' contains all the homework grades read so far
while (cin >> x)
homework.push_back(x);
// check that the student entered some homework grades
typedef vector<double>::size_type vec_sz;
vec_sz size = homework.size();
if (size == 0) {
cout << endl << "You must enter your grades. "
"Please try again." << endl;
return 1;
}
// sort the grades
sort(homework.begin(), homework.end());
// compute the median homework grade
vec_sz mid = size/2;
double median;
median = size % 2 == 0 ? (homework[mid] + homework[mid-1]) / 2
: homework[mid];
// compute and write the final grade
streamsize prec = cout.precision();
cout << "Your final grade is " << setprecision(3)
<< 0.2 * midterm + 0.4 * final + 0.4 * median
<< setprecision(prec) << endl;
return 0;
}
- 中值避免了一些糟糕的成绩让平均成绩下降太多
vector类型表示向量,长度可变vector<double>::size_type是一个 unsigned 类型,保存向量长度。type_def把 vec_sz 设置成了vector<double>::size_type的替代名- sort -- 排序
- 普通整数和无符号整数结合,普通整数会被转换成无符号整数
- C++ 强调速度,为注重性能的应用服务
04 组织程序和数据 ¶
4.1 组织计算 ¶
C++
#include <stdexcept>
#include <vector>
#include "grade.h"
#include "median.h"
#include "Student_info.h"
using std::domain_error; using std::vector;
// compute a student's overall grade from midterm and final exam grades and homework grade
double grade(double midterm, double final, double homework)
{
return 0.2 * midterm + 0.4 * final + 0.4 * homework;
}
// compute a student's overall grade from midterm and final exam grades
// and vector of homework grades.
// this function does not copy its argument, because `median' does so for us.
double grade(double midterm, double final, const vector<double>& hw)
{
if (hw.size() == 0)
throw domain_error("student has done no homework");
return grade(midterm, final, median(hw));
}
double grade(const Student_info& s)
{
return grade(s.midterm, s.final, s.homework);
}
- 按值调用: 参数获得的只是参数值的一个复制,
double grade(double midterm, double final, double homework) - 引用:
vector<double>& hw对 hw 操作相当于对 homework 操作 - 异常:
- 如果向量为空就抛出一个异常,程序会在抛出异常的地方中止执行并转移到程序的另一部分 ( 类似 python 中的 try-except 语句 ),并向这一部分提供一个异常对象
domain_error告诉我们取值有问题,我们自定义字符串描述错误信息- 左值参数:指示非临时变量的值
读取逻辑优化
C++
// read homework grades from an input stream into a `vector<double>'
istream& read_hw(istream& in, vector<double>& hw)
{
if (in) {
// get rid of previous contents
hw.clear();
// read homework grades
double x;
while (in >> x)
hw.push_back(x);
// clear the stream so that input will work for the next student
in.clear(); // avoid failure by wrong input
}
return in;
}
vector<double>& hw是引用,节省了复制的开销- 三种参数类型
vector<double>const vector<double>vector<double>&
try-catch语句示例
C++
try {
double final_grade = grade(midterm, final, homework);
streamsize prec = cout.precision();
cout << "Your final grade is " << setprecision(3)
<< final_grade << setprecision(prec) << endl;
} catch (domain_error) {
cout << endl << "You must enter your grades. "
"Please try again." << endl;
return 1;
}
- 保证一条语句的副作用个数不会超过一个,抛出一个异常是一个副作用,因此在一条可能会引发异常的语句中不应该再出现任何其他的副作用,尤其是哪些包含有输入和输出的语句。上面的语句满足了这个要求,没有把 final_grade 放入输入输出语句中。
4.2 组织数据 ¶
C++
int main()
{
vector<Student_info> students;
student_info record;
string::size_type maxlen = 0;
//读并存储所有的记录,然后找出最长的姓名的长度
while(read(cin, record))
{
maxlen = max(maxlen, record.name.size());
students.push_back(record);
}
//按字母顺序排列记录
sort(Students.begin(), students.end(), compare);
for (vector<Student_info>::size_type i = 0; i != students.size(); i++)
{
//输出姓名,填充姓名以达到maxlen + 1的长度
cout << setw(maxlen + 1) << students[i].name;
}
//计算并输出成绩
try
{
double final_grade = grade(students[i]);
streamsize prec = cout.precision();
cout << setprecision(3) << final_grade << setprecision(prec);
}
catch(domain_error e){
cout << e.what();
}
cout << endl;
return 0;
}
- max 函数在
algorithm中定义 - e 是异常的名称,这样就可以输出 what() 中的信息。
4.3 把各部分代码连接到一起 ¶
- 组装 median 函数
C++
// median 函数的源文件 -- median.cpp
#include <algorithm> // to get the declaration of `sort'
#include <stdexcept> // to get the declaration of `domain_error'
#include <vector> // to get the declaration of `vector'
using std::domain_error; using std::sort; using std::vector;
#include "median.h"
// compute the median of a `vector<double>'
// note that calling this function copies the entire argument `vector'
double median(vector<double> vec)
{
typedef vector<double>::size_type vec_sz;
vec_sz size = vec.size();
if (size == 0)
throw domain_error("median of an empty vector");
sort(vec.begin(), vec.end());
vec_sz mid = size/2;
return size % 2 == 0 ? (vec[mid] + vec[mid-1]) / 2 : vec[mid];
}
- 需要包含 median 函数使用的所有名称的声明。
- 如何在别的文件使用 median 函数
- 自己的文件称作头文件,系统环境提供的头文件称作标准头
C++
//median.h 最终形式
#ifndef GUARD_median_h
#define GUARD_median_h
#include <vector>
double median(std::vector<double>);
#endif
- 头文件应该有什么
- median 的声明
- 保证 vector 可用,所以要有 vector 头
- 头文件应该使用完整的限定名而不是 using 声明
#ifndef检查 median.h 是否被重复包含,必须位于文件的第一行
- median 的声明
4.4 把计算成绩的程序分块 ¶
C++
#ifndef GUARD_Student_info
#define GUARD_Student_info
// `Student_info.h' 头文件
#include <iostream>
#include <string>
#include <vector>
struct Student_info {
std::string name;
double midterm, final;
std::vector<double> homework;
};
bool compare(const Student_info&, const Student_info&);
std::istream& read(std::istream&, Student_info&);
std::istream& read_hw(std::istream&, std::vector<double>&);
#endif
C++
// median.cpp 源文件
#include "Student_info.h"
using std::istream; using std::vector;
bool compare(const Student_info& x, const Student_info& y)
{
return x.name < y.name;
}
istream& read(istream& is, Student_info& s)
{
// read and store the student's name and midterm and final exam grades
is >> s.name >> s.midterm >> s.final;
read_hw(is, s.homework); // read and store all the student's homework grades
return is;
}
// read homework grades from an input stream into a `vector<double>'
istream& read_hw(istream& in, vector<double>& hw)
{
if (in) {
// get rid of previous contents
hw.clear();
// read homework grades
double x;
while (in >> x)
hw.push_back(x);
// clear the stream so that input will work for the next student
in.clear();
}
return in;
}
- 源文件中包含头文件可以检查声明和定义是否一致
4.5 修正后的计算成绩的程序 ¶
C++
#include <algorithm>
#include <iomanip>
#include <ios>
#include <iostream>
#include <stdexcept>
#include <string>
#include <vector>
#include "grade.h"
#include "Student_info.h"
using std::cin; using std::setprecision;
using std::cout; using std::sort;
using std::domain_error; using std::streamsize;
using std::endl; using std::string;
using std::max; using std::vector;
int main()
{
vector<Student_info> students;
Student_info record;
string::size_type maxlen = 0; // the length of the longest name
// read and store all the students' data.
// Invariant: `students' contains all the student records read so far
// `maxlen' contains the length of the longest name in `students'
while (read(cin, record)) {
// find length of longest name
maxlen = max(maxlen, record.name.size());
students.push_back(record);
}
// alphabetize the student records
sort(students.begin(), students.end(), compare);
// write the names and grades
for (vector<Student_info>::size_type i = 0;
i != students.size(); ++i) {
// write the name, padded on the right to `maxlen' `+' `1' characters
cout << students[i].name
<< string(maxlen + 1 - students[i].name.size(), ' ');
// compute and write the grade
try {
double final_grade = grade(students[i]);
streamsize prec = cout.precision();
cout << setprecision(3) << final_grade
<< setprecision(prec);
} catch (domain_error e) {
cout << e.what();
}
cout << endl;
}
return 0;
}
4.6 小结 ¶
#include <系统头>:系统头可能不是以文件的形式实现的#include "自定义头文件":通常有后缀.h- 结构的定义在每一个源文件中只可以出现一次,因此它应该出现在一个有适当防护措施的头文件中。
05 使用顺序容器并分析字符串 ¶
5.1 按类别来区分学生 ¶
- 在除了向量结尾的其他地方插入或删除元素的开销可能会很大
5.2 迭代器 ¶
- 迭代器(iterator) 能够
- 识别一个容器以及容器中的一个元素
- 检查存储在这个元素中的值
- 提供操作来移动在容器中的元素
- 采用对应于容器所能够有效处理的方式来对可用的操作进行约束
C++
for (vector<Student_info>::size_type i = 0; i!= students.sizes(); ++i)
cout << students[i].name << endl;
// OR
for (vector<Student_info>::const_iterator iter = students.begin(); iter != students.end(); ++iter)
cout << (*iter).name << endl;
- 每一个标准容器都定义了两种相关的迭代器类型
container-type::const_iterator如果仅仅读选用这个container-type::iterator
(*iter).name可以写为iter->name
5.3 用迭代器代替索引 ¶
iter = students.erase(iter)只是删除 iter 会使迭代器失效,因为 iter 指向的元素已经消失了,这个语句会让 iter 指向被删除元素后面的的那个元素。
5.4 重新思考数据结构以实现更好的性能 ¶
5.5 list 类型 ¶
- list 类型在
<list>头文件中定义 - list 不支持索引,但是支持迭代器
- 对 list 来说,erase 和 push_back 操作不会使指向其他元素的迭代器失效,只有指向已被删除的元素的迭代器才会失效。
- 不能使用标准库的 sort 函数来为存储在 list 中的值排序。
这是 list 类提供的 sort 成员函数
对比 vector
- 小规模输入 list 效率要比 vector 低
- 大规模的输入,vector 性能会飞速下降
5.6 分割字符串 ¶
- substr 是 string 类的一个成员
- 从第一个参数给定的索引开始复制字符,复制的字符个数由第二个参数指定。
5.7 测试 split 函数 ¶
C++
int main()
{
string s;
// read and split each line of input
while (getline(cin, s)) {
vector<string> v = split(s);
// write each word in `v'
for (vector<string>::size_type i = 0; i != v.size(); ++i)
cout << v[i] << endl;
}
return 0;
}
getline:- 第一个参数是一个输入流,第二个参数是一个字符串引用,作用是把从输入流中读取到的数据存在字符串引用中。
- 返回值逻辑和 cin 相同
- 读取一行输入
5.8 连接字符串 ¶
5.9 小结 ¶
c.begin指向容器第一个元素的迭代器c.end()指向紧跟在最后一个位置之后的那个位置的迭代器。
06 使用库算法 ¶
6.1 分析字符串 ¶
C++
for(vector<string>::const_iterator it = bottom.begin(); it != bottom.end(); ++it)
{
ret.push_back(*it)
}
// OR
ret.insert(ret.end(), bottom.begin(), bottom.end());
// OR
copy(bottom.begin(), bottom.end(), back_intserter(ret));
- 迭代器适配器是把某个容器作为参数并产生一个迭代器
- back_inserter 就是一个迭代器适配器
C++
vector<string> split(const string& str)
{
typedef string::const_iterator iter;
vector<string> ret;
iter i = str.begin();
while (i != str.end()) {
// ignore leading blanks
i = find_if(i, str.end(), not_space);
// find end of next word
iter j = find_if(i, str.end(), space);
// copy the characters in `[i,' `j)'
if (i != str.end())
ret.push_back(string(i, j));
i = j;
}
return ret;
}
find_if: 头两个参数是迭代器 , 第三个参数是一个谓词,它会检测自己的参数然后返回 true 或 false. 当碰到 true 时停止并返回当前的迭代器substr对索引进行操作,string (i, j) 是区间 (i, j) 中的字符的一个复件
C++
bool is_palindrome(const string& s)
{
return equal(s.begin(), s.end(), s.rbegin());
}
int main()
{
string s;
while (cin >> s) {
if (is_palindrome(s))
cout << s << " is a palindrome" << endl;
else
cout << s << " is not a palindrome" << endl;
}
return 0;
}
equal: 比较两个序列是否包含有相等的值,前两个参数指定了第一个序列,第三个参数是第二个序列的起点,equal 函数假定第二个序列的长度和第一个相同。rbegin()从结尾向前逆向地比较数。
查找 URL:
- URL:
protocol://resource-name- protocol 是协议名称,仅包含字母,resource 可以由字母数字和某些标点组成
C++
vector<string> find_urls(const string& s)
{
vector<string> ret;
typedef string::const_iterator iter;
iter b = s.begin(), e = s.end();
// look through the entire input
while (b != e) {
// look for one or more letters followed by `://'
b = url_beg(b, e);
// if we found it
if (b != e) {
// get the rest of the \s-1URL\s0
iter after = url_end(b, e);
// remember the \s-1URL\s0
ret.push_back(string(b, after));
// advance `b' and check for more \s-1URL\s0s on this line
b = after;
}
}
return ret;
}
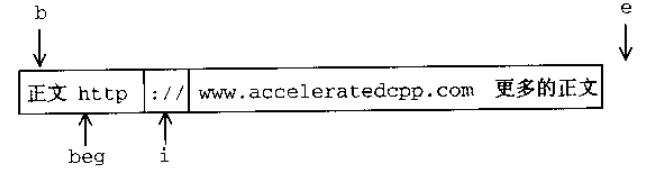
C++
url_end(string::const_iterator b, string::const_iterator e)
{
return find_if(b, e, not_url_char);
}
C++
bool not_url_char(char c)
{
// characters, in addition to alphanumerics, that can appear in a \s-1URL\s0
static const string url_ch = "~;/?:@=&$-_.+!*'(),";
// see whether `c' can appear in a \s-1URL\s0 and return the negative
return !(isalnum(c) ||
find(url_ch.begin(), url_ch.end(), c) != url_ch.end());
}
- static 声明地局部变量具有全局寿命,
- find :如果查找的值存在的话,那么函数返回第一个指向这个值的迭代器,否则返回第二个参数。
C++
url_beg(string::const_iterator b, string::const_iterator e)
{
static const string sep = "://";
typedef string::const_iterator iter;
// `i' marks where the separator was found
iter i = b;
while ((i = search(i, e, sep.begin(), sep.end())) != e) {
// make sure the separator isn't at the beginning or end of the line
if (i != b && i + sep.size() != e) {
// `beg' marks the beginning of the protocol-name
iter beg = i;
while (beg != b && isalpha(beg[-1]))
--beg;
// is there at least one appropriate character before and after the separator?
if (beg != i && !not_url_char(i[sep.size()]))
return beg;
}
// the separator we found wasn't part of a \s-1URL\s0; advance `i' past this separator
i += sep.size();
}
return e;
}
search: 第一对参数指示了要查找的序列,第二队指示了一个序列,如果 search 失败将返回第二个迭代器,找到了就返回sep.begin()beg[-1]即*(beg - 1)
6.2 对计算成绩的方案进行比较 ( 可读性很差 ) ¶
6.5 小结 ¶
accumulate(b, e, t)find(b,e,t)find_if(b,e,t)search(b,e,b2,e2)
07 使用关联容器 ¶
7.1 支持高效查找的容器 ¶
- " 键 - 值 " 对 , 这种数据结构被称为关联数组
- C++ 中常用的一种关联数组是 map, 在
<map>中定义 - 关联容器自动排序
7.2 计算单词数 ¶
C++
int main()
{
string s;
map<string, int> counters; // store each word and an associated counter
// read the input, keeping track of each word and how often we see it
while (cin >> s)
++counters[s];
// write the words and associated counts
for (map<string, int>::const_iterator it = counters.begin();
it != counters.end(); ++it) {
cout << it->first << "\t" << it->second << endl;
}
return 0;
}
- 要指定键值类型
- 添加键的时候值会被初始化
- 重复访问映射表的时候实际上使用了数对
- 数对(pair)
- 包含 first 和 second
- 键类型为 K,值类型为 V 的映射表,
pair<const K, V> - 禁止修改键的值
7.3 产生一个交叉引用表 ¶
C++
map<string, vector<int> >
xref(istream& in,
vector<string> find_words(const string&) = split)
{
string line;
int line_number = 0;
map<string, vector<int> > ret;
// read the next line
while (getline(in, line)) {
++line_number;
// break the input line into words
vector<string> words = find_words(line);
// remember that each word occurs on the current line
for (vector<string>::const_iterator it = words.begin();
it != words.end(); ++it)
ret[*it].push_back(line_number);
}
return ret;
}
vector<string> find_words(const string&) = split是一个缺省参数xref(cin)则调用 splitxref(cin, find_urls)则调用 find_urls
产生交叉引用表
C++
int main()
{
// call `xref' using `split' by default
map<string, vector<int> > ret = xref(cin);
// write the results
for (map<string, vector<int> >::const_iterator it = ret.begin();
it != ret.end(); ++it) {
// write the word
cout << it->first << " occurs on line(s): ";
// followed by one or more line numbers
vector<int>::const_iterator line_it = it->second.begin();
cout << *line_it; // write the first line number
++line_it;
// write the rest of the line numbers, if any
while (line_it != it->second.end()) {
cout << ", " << *line_it;
++line_it;
}
// write a new line to separate each word from the next
cout << endl;
}
return 0;
}
7.4 生成句子 ¶
- 读入文法
C++
typedef vector<string> Rule;
typedef vector<Rule> Rule_collection;
typedef map<string, Rule_collection> Grammar;
// read a grammar from a given input stream
Grammar read_grammar(istream& in)
{
Grammar ret;
string line;
// read the input
while (getline(in, line)) {
// `split' the input into words
vector<string> entry = split(line);
if (!entry.empty())
// use the category to store the associated rule
ret[entry[0]].push_back(
Rule(entry.begin() + 1, entry.end()));
}
return ret;
}
- gen_aux 使用文法 g 并按照
<sentence>规则生成一个句子
C++
void gen_aux(const Grammar&, const string&, vector<string>&);
int nrand(int);
vector<string> gen_sentence(const Grammar& g)
{
vector<string> ret;
gen_aux(g, "<sentence>", ret);
return ret;
}
bool bracketed(const string& s)
{
return s.size() > 1 && s[0] == '<' && s[s.size() - 1] == '>';
}
void
gen_aux(const Grammar& g, const string& word, vector<string>& ret)
{
if (!bracketed(word)) {
ret.push_back(word);
} else {
// locate the rule that corresponds to `word'
Grammar::const_iterator it = g.find(word);
if (it == g.end())
throw logic_error("empty rule");
// fetch the set of possible rules
const Rule_collection& c = it->second;
// from which we select one at random
const Rule& r = c[nrand(c.size())];
// recursively expand the selected rule
for (Rule::const_iterator i = r.begin(); i != r.end(); ++i)
gen_aux(g, *i, ret);
}
}
- 使用这些函数
C++
int main()
{
// generate the sentence
vector<string> sentence = gen_sentence(read_grammar(cin));
// write the first word, if any
vector<string>::const_iterator it = sentence.begin();
if (!sentence.empty()) {
cout << *it;
++it;
}
// write the rest of the words, each preceded by a space
while (it != sentence.end()) {
cout << " " << *it;
++it;
}
cout << endl;
return 0;
}
- 编写 nrand
<cstdlib>中包含了一个名为 rand 的函数,不含参数,返回[0, RAND_MAX]中的一个随机整数,这里 RAND_MAX 是一个大整数,也在<cstdlib>中定义,- 使用 rand () % n 会使得一些余数出现的频率更高,假定 RAND_MAX 为 32767 那么出现 10000 的情况有 30000 % 20000 = 10000,10000 % 20000 = 10000,而出现 15000 的情况只有 15000 % 20000 = 15000
- 我们使用存储桶的方法
C++
int nrand(int n)
{
if (n <= 0 || n > RAND_MAX)
throw domain_error("Argument to nrand is out of range");
const int bucket_size = RAND_MAX / n;
int r;
do r = rand() / bucket_size;
while (r >= n);
return r;
}
7.5 关于性能的说明 ¶
7.6 小结 ¶
pair<k, v>保存了一对数值,通过 first 和 second 来访问map<k, v>是一个关联数组,键为 K,值为 V。如果 iter 是指向某个元素的迭代器,可以用 iter->first, iter->second 来访问键和值map<k, v> mm.find(k)返回一个迭代器,这个迭代器指向键为 K 的元素
08 编写泛型函数 ¶
8.1 泛型函数是什么 ¶
C++
template <class T>
T median(vector<T> v)
{
typedef typename vector<T>::size_type vec_sz;
vec_sz size = v.size();
if (size == 0)
throw domain_error("median of an empty vector");
sort(v.begin(), v.end());
vec_sz mid = size/2;
return size % 2 == 0 ? (v[mid] + v[mid-1]) / 2 : v[mid];
}
- 实现了泛型函数的语言特征被称为模板函数
template<class T>告知系统环境我们定义了一个模板函数typename告知系统环境后面的内容是一个类型名- 如果用
<vector<int>类型调用 median,那么 int 会代替所有 T 的使用
C++
// 这个函数不能通过编译,
template <class T>
T max(const T& left, const T& right)
{
return left > right ? left : right;
}
8.2 数据结构独立性 ¶
09 定义新类型 ¶
9.1 回顾一下 Student_info ¶
9.2 自定义类型 ¶
C++
struct Student_info(){
std:: string name;
double midterm, final;
std:: vector<double> homework;
}
- 类的声明常常在头文件中,一般没有 using 声明
9.2.1 成员函数 ¶
C++
struct Student_info(){
std:: string name;
double midterm, final;
std:: vector<double> homework;
std::istream(std::istream&);
double grade() const; // const 说明不会修改成员变量
}
C++
istream& Student_info::read(istream& in)
{
in >> n >> midterm >> final;
read_hw(in, homework);
return in;
}
- read 函数将被放入名为
Student_info.cpp的源文件中。 - 函数名是
Student_info::read而不是read, 因为这个函数是Student_info的成员 - 可以直接访问对象的数据元素。
::grade如果我们把::放在一个名称之前那就表明我们要使用这个名称的某一个版本,而这个版本不是任何结构体的成员。- 不能对常量对象调用非常量函数
- 常量成员函数不能改变对象的内部状态
9.3 保护 ¶
C++
class Student_info {
public:
Student_info(); // construct an empty `Student_info' object
Student_info(std::istream&); // construct one by reading a stream
std::string name() const { return n; }
bool valid() const { return !homework.empty(); }
// as defined in 9.2.1/157, and changed to read into `n' instead of `name'
std::istream& read(std::istream&);
double grade() const; // as defined in 9.2.1/158
private:
std::string n;
double midterm, final;
std::vector<double> homework;
};
class和struct的差别class缺省为私有,struct缺省为公有
9.3.1 存取器函数 ¶
compare():
9.4 Student_info 类 ¶
C++
class Student_info {
public:
Student_info(); // construct an empty `Student_info' object
Student_info(std::istream&); // construct one by reading a stream
std::string name() const { return n; }
bool valid() const { return !homework.empty(); }
// as defined in 9.2.1/157, and changed to read into `n' instead of `name'
std::istream& read(std::istream&);
double grade() const; // as defined in 9.2.1/158
private:
std::string n;
double midterm, final;
std::vector<double> homework;
};
- 用户只能通过调用 read 函数改变对象状态,不能进入内部修改任何的数据成员。
9.5 构造函数 ¶
- 缺省构造函数
Student_info():
- 带参构造函数
Student_info(istream& is) { read(is);}
9.6 使用 Student_info 类 ¶
C++
int main()
{
vector<Student_info> students;
Student_info record;
string::size_type maxlen = 0;
// read and store the data
while (record.read(cin)) { // changed
maxlen = max(maxlen, record.name().size()); // changed
students.push_back(record);
}
// alphabetize the student records
sort(students.begin(), students.end(), compare);
// write the names and grades
for (vector<Student_info>::size_type i = 0;
i != students.size(); ++i) {
cout << students[i].name() // this and the next line changed
<< string(maxlen + 1 - students[i].name().size(), ' ');
try {
double final_grade = students[i].grade(); // changed
streamsize prec = cout.precision();
cout << setprecision(3) << final_grade
<< setprecision(prec) << endl;
} catch (domain_error e) {
cout << e.what() << endl;
}
}
return 0;
}
9.7 小结 ¶
- 保护标识符
- 成员函数
- 构造函数
- 构造函数初始化程序列表