零碎的知识 ¶
约 1631 个字 16 行代码 预计阅读时间 8 分钟
这里放置一些不成体系的小知识点 仍在更新!
1 typeof & define¶
只可意会,看下面的例子
此时a,b都是指针变量。 此时等同于 只有a为指针变量,而b为整型变量。2 符号位的扩展 ¶
Text Only
int main()
{
char a = -56;
char b = -256;
char c = -512;
char d = 128;
char e = 64;
printf("%u %u %u %u %u", a,b,c,d,e);
//128二进制原码10000000000000000000000010000000
//128二进制补码11111111111111111111111110000000
//存到a中为10000000
//u为打印无符号整形,类型提升为11111111111111111111111110000000
//打印出一个很大的数字。
//10000000000000000000000100000000 -256的原码
//11111111111111111111111100000000 补码
//存到a中为00000000
//类型提升后为00000000000000000000000000000000
//类型提升提升的是原来的符号位比如10000000类型提升后就往前面加1,01000000提升就往前面加0
//对于d来说看似是个正数,符号位是0类型提升也应该补0,但是被char 类型截断后是个负数,所以类型提升还是往前补1
return 0;
}
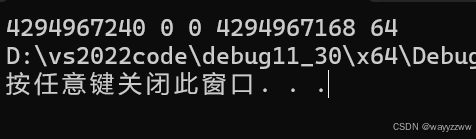
运行结果
PS char 类型的取值范围
0000000
0000001
0111111
1000000
1000001
1111111
取值范围是 -128->127
3 scanf()¶
问: 你是一名擅长C语言的专业教授,我是C语言的初学者,请你结合缓冲区的变化详细分析一下输入3\n\n\naha\n后下列程序会产生什么输出结果
C
[GPT4o] 答: - 缓冲区变化的逐步分析 int main()
{
int x;
char ch1, ch2, ch3;
scanf("%d\n", &x);
printf("%d", x);
ch1 = getchar();
ch2 = getchar();
ch3 = getchar();
printf("hello");
printf("%c%c%c", ch1, ch2, ch3);
return 0;
}
假设用户按下键盘输入 3\n\n\naha\n,缓冲区的初始内容如下:
- 第一步:执行
scanf("%d\n", &x);
scanf的%d:%d会读取缓冲区中的整数,3被成功读取到变量x中;-
缓冲区剩下:
-
%d\n的\n: %d\n中的\n表示“忽略空白字符(包括空格和换行)”:- 它会跳过一个或多个换行符(或者其他空白字符
) ,直到遇到非空白字符才停止; -
因此,
scanf会消费掉所有的换行符\n\n\n,缓冲区剩下: -
变量状态:
x = 3- 缓冲区剩下:
- 第二步:执行
printf("%d", x);
- 打印变量
x的值: 输出:3
- 第三步:执行
ch1 = getchar();
getchar从缓冲区中读取一个字符:- 缓冲区当前内容为
aha\n; getchar读取第一个字符a,将其赋值给ch1;- 缓冲区剩下:
- 第四步:执行
ch2 = getchar();
getchar再次从缓冲区中读取一个字符:- 缓冲区当前内容为
ha\n; getchar读取第一个字符h,将其赋值给ch2;- 缓冲区剩下:
- 第五步:执行
ch3 = getchar();
getchar再次从缓冲区中读取一个字符:- 缓冲区当前内容为
a\n; getchar读取第一个字符a,将其赋值给ch3;- 缓冲区剩下:
- 第六步:执行
printf("hello");
- 打印字符串
hello: 输出:hello
- 第七步:执行
printf("%c%c%c", ch1, ch2, ch3);
- 打印字符
ch1,ch2, 和ch3: ch1 = 'a'ch2 = 'h'ch3 = 'a'输出:aha
最终输出
将所有的输出汇总,程序输出为:
总结
缓冲区在输入过程中会动态变化:
scanf中的%d\n会读取整数并消费多余的换行符;getchar从缓冲区逐个读取字符,依次消耗。
输入 3\n\n\naha\n 按顺序处理后:
x = 3ch1 = 'a'ch2 = 'h'ch3 = 'a'
最终输出为:
4 大小端 ¶
在计算机中,大小端是指在多字节数据(如整数、浮点数等)存储在内存中的字节顺序。不同的计算机架构可能使用不同的字节顺序来存储数据,通常有两种方式:大端和小端
- 大端
- 在大端模式下,数据的高字节存储在低地址(内存的起始位置
) ,低字节存储在高地址。
例子: 假设你有一个 32 位整数 0x12345678,它由 4 个字节组成,分别是: - 0x12(高字节) - 0x34 - 0x56 - 0x78(低字节)
在大端模式下,这个整数将按如下顺序存储在内存中:
| 地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 数据 | 0x12 | 0x34 | 0x56 | 0x78 |
- 小端 - 在小端模式下,数据的低字节存储在低地址,高字节存储在高地址。
例子: 对于同样的 32 位整数 0x12345678,在小端模式下,它将按如下顺序存储:
| 地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 数据 | 0x78 | 0x56 | 0x34 | 0x12 |
大小端的影响
- 数据交换问题:不同的计算机架构可能使用不同的字节顺序,导致在跨平台或跨网络传输时,数据解释不一致。
- 网络协议:例如,TCP/IP 协议通常使用大端顺序(网络字节顺序)来确保跨网络的数据一致性。
示例:整数 0x01020304 的存储方式
- 大端存储:
| 地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 数据 | 0x01 | 0x02 | 0x03 | 0x04 |
- 小端存储:
| 地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 数据 | 0x04 | 0x03 | 0x02 | 0x01 |
为什么要区分大小端?
- 兼容性:不同硬件架构(如 x86 使用小端,某些 RISC 架构使用大端)可能需要不同的字节顺序。
- 性能优化:一些处理器在特定字节顺序下的性能更好,因此操作系统和程序可能根据平台调整字节顺序。
总结
- 大端:将数据的高字节存储在低地址。
- 小端:将数据的低字节存储在低地址。
- 应用:在跨平台或网络通信中,理解大小端是非常重要的。
5 const 和 define 定义不变量时的区别 ¶
示例: const int N = 100; 和 #define N 100; 的区别
const int N = 100;
- 类型安全 : const 定义了一个类型安全的常量,具有明确的类型(在这里是 int
) 。 - 作用域 : const 常量遵循 C++ 的作用域规则,可以是局部的或全局的。
- 调试友好 : 在调试时,const 常量可以更容易地被识别和检查。
- 编译时常量 : 可以用于需要编译时常量的上下文中,如数组大小。
#define N 100;
- 宏定义 : #define 定义的是一个宏,宏是预处理器指令,在编译之前进行文本替换。
- 类型不安全 : 宏定义没有类型检查,可以用于任何类型。
- 作用域 : 宏定义的作用域通常是全局的,但也可以在局部范围内定义。
- 调试困难 : 宏定义在调试时不容易被识别和检查。
- 编译时替换 : 宏在编译时被展开,因此可以用于需要编译时替换的上下文中,如数组大小。