CS61A_notes¶
约 5684 个字 988 行代码 9 张图片 预计阅读时间 41 分钟
1 使用函数构建抽象 ¶
1.1 开始 ¶
1.2 编程要素 ¶
- 纯函数和非纯函数
- 非纯函数 : 除了返回值外,调用一个非纯函数还会产生其他改变解释器和计算机的状态的副作用(side effect
) 。一个常见的副作用就是使用print函数产生(非返回值的)额外输出。 - 纯函数:函数有一些输入(参数)并返回一些输出(调用返回结果
) 。
示例:
- 非纯函数 : 除了返回值外,调用一个非纯函数还会产生其他改变解释器和计算机的状态的副作用(side effect
1.3 定义新的函数 ¶
- 如何定义函数:
示例:
- 当函数没有显式 return,默认返回 None 值
示例:
- 一个函数可以有多个返回值
示例:
1.4 设计函数 ¶
1.4.1 文档 ¶
函数定义通常包括描述函数的文档,称为“文档字符串 docstring”,它必须在函数体中缩进。文档字符串通常使用三个引号,第一行描述函数的任务,随后的几行可以描述参数并解释函数的意图:
>>> def pressure(v, t, n):
"""计算理想气体的压力,单位为帕斯卡
使用理想气体定律:http://en.wikipedia.org/wiki/Ideal_gas_law
v -- 气体体积,单位为立方米
t -- 绝对温度,单位为开尔文
n -- 气体粒子
"""
k = 1.38e-23 # 玻尔兹曼常数
return n * k * t / v
当你使用函数名称作为参数调用 help 时,你会看到它的文档字符串(键入 q 以退出 Python help
编写 Python 程序时,除了最简单的函数之外,都要包含文档字符串。要记住,虽然代码只编写一次,但是会在之后阅读多次。Python 文档包含了 文档字符串准则,它会在不同的 Python 项目中保持一致。
注释:Python 中的注释可以附加到 # 号后的行尾。例如,上面代码中的注释 玻尔兹曼常数 描述了 k 变量的含义。这些注释不会出现在 Python 的 help 中,而且会被解释器忽略,它们只为人类而存在。
1.4.2 参数默认值 ¶
>>> def pressure(v, t, n=6.022e23):
"""计算理想气体的压力,单位为帕斯卡
使用理想气体定律:http://en.wikipedia.org/wiki/Ideal_gas_law
v -- 气体体积,单位为立方米
t -- 绝对温度,单位为开尔文
n -- 气体粒子,默认为一摩尔
"""
k = 1.38e-23 # 玻尔兹曼常数
return n * k * t / v
1.5 控制 ¶
1.5.1 语句 ¶
1.5.2 复合语句 ¶
1.5.3 定义函数 II:局部赋值 ¶
1.5.4 条件语句 ¶
语法 :
1.5.5 迭代 ¶
语法 :
1.5.6 测试 ¶
assert-断言:断言(Assertions) :程序员使用assert语句来验证是否符合预期,例如验证被测试函数的输出。assert语句在布尔上下文中有一个表达式,后面是一个带引号的文本行(单引号或双引号都可以,但要保持一致)- 如果表达式的计算结果为假值,则显示该行。
- 当被断言的表达式的计算结果为真值时,执行断言语句无效。而当它是假值时,
assert会导致错误,使程序停止执行。
示例:
def fib(n):
if n < 2:
return 1
else:
a, b = 1, 1
while n - 2:
a, b = b,a + b
n = n - 1
return b
def fib_test():
assert fib(2) == 1, '第二个斐波那契数应该是 1'
assert fib(3) == 2, '第三个斐波那契数应该是 1'
fib_test()
1.6 高阶函数 ¶
1.6.0 高阶函数的定义 ¶
在 Python 中,高阶函数(Higher-order function)是指:
- 接受一个或多个函数作为参数,或者
- 返回一个函数作为结果。
高阶函数的核心思想是:函数可以像数据一样传递。你可以将函数作为参数传递给另一个函数,或者将函数作为返回值返回。
高阶函数的特征
- 接受函数作为参数:例如,
map()、filter()、sorted()等内置函数。 - 返回一个函数:例如,Python 中的装饰器(decorators)就是一个常见的例子。
课程视频中的部分笔记:
不同于平常的 if 控制语句,调用 if_ 这个函数的前会把所有参数求出来
from math import sqrt
def if_(c,t,f):
if c:
return t
else:
return f
def real_sqrt(x):
return if_(x >= 0,sqrt(x),0)
print(real_sqrt(-16))
报错!
Traceback (most recent call last):
File "c:\Users\am\Desktop\python\text.py", line 11, in <module>
print(real_sqrt(-16))
^^^^^^^^^^^^^^
File "c:\Users\am\Desktop\python\text.py", line 8, in real_sqrt
return if_(x >= 0,sqrt(x),0)
^^^^^^^
ValueError: math domain error
1.6.1 作为参数的函数 ¶
示例:
>>> def summation(n, term):
total, k = 0, 1
while k <= n:
total, k = total + term(k), k + 1
return total
>>> def identity(x):
return x
>>> def sum_naturals(n):
return summation(n, identity)
>>> sum_naturals(10)
55
1.6.2 作为通用方法的函数 ¶
- 迭代改进算法通用表达式
>>> def improve(update, close, guess=1):
while not close(guess):
guess = update(guess)
return guess
迭代改进算法求黄金分割:
def improve(update,close,guess=1):
while not close(guess):
guess = update(guess)
return guess
def approx_eq(x,y,tolerance = 1e-15):
return abs(x - y) < tolerance
def golden_update(x):
return 1/x + 1
def golden_close(x):
return approx_eq(x * x,x + 1)
print(improve(golden_update,golden_close))
测试代码:
from math import sqrt
phi = 1/2 + sqrt(5)/2
def improve_test():
approx_phi = improve(golden_update, golden_close)
assert approx_eq(phi, approx_phi), 'phi differs from its approximation'
improve_test()
1.6.3 定义函数 III: 嵌套定义 ¶
- 闭包:在 Python 中,当一个函数返回一个嵌套的函数时,嵌套函数会“捕获”外部函数的变量。这个特性叫做 闭包。闭包使得嵌套函数可以访问并修改外部函数中的变量,即使外部函数已经执行完毕。
- 可变对象(如列表、字典)在嵌套函数中修改时,不需要
nonlocal,因为修改的是对象的内部内容,而不是创建一个新的变量。 - 不可变对象(如整数、浮点数、字符串)在嵌套函数中修改时,默认会创建一个新的局部变量,因此需要使用
nonlocal来修改外部函数中的变量。
1.6.4 作为返回值的函数 ¶
示例:
1.6.5 示例:牛顿法 ¶
1.6.6 柯里化 (Curring) ¶
示例:pow 函数的柯里化版本
from math import pow
def curry(x):
def f(y):
return pow(x,y)
return f
h = curry(2)
print(h(3))
print(curry(2)(3))
上面的例子手动进行了 pow 函数的柯里化变换,也可以定义函数来了自动进行柯里化以及逆柯里化
示例:
>>> def curry2(f):
"""返回给定的双参数函数的柯里化版本"""
def g(x):
def h(y):
return f(x, y)
return h
return g
>>> def uncurry2(g):
"""返回给定的柯里化函数的双参数版本"""
def f(x, y):
return g(x)(y)
return f
>>> pow_curried = curry2(pow)
>>> pow_curried(2)(5)
32
>>> map_to_range(0, 10, pow_curried(2))
1
2
4
8
16
32
64
128
256
512
1.6.7 Lambda 表达式 ¶
例如复合 f 和 g 两个函数的时候(1.6.3)
还可以写作:
逻辑如下:
PS:更简洁的写法
1.6.8 抽象和一等函数 ¶
一般而言,编程语言会对计算元素的操作方式施加限制。拥有最少限制的元素可以获得一等地位(first-class status
- 可以与名称绑定
- 可以作为参数传递给函数
- 可以作为函数的结果返回
- 可以包含在数据结构中
Python 授予函数完全的一等地位,由此带来的表达能力的提升是巨大的。
1.6.9 函数装饰器 ¶
1.6.10 self-reference¶
示例:
>>> def print_all(x):
... print(x)
... return print_all
...
>>> print_all(1)(2)(100)
1
2
100
<function print_all at 0x000002E6A80AF560>
>>> def print_sum(x):
... print(x)
... def h(y):
... return print_sum(x + y)
... return h
...
>>> print_sum(1)(3)(3)(5)
1
4
7
12
<function print_sum.<locals>.h at 0x000002E6A80AF6A0>
1.7 递归函数 ¶
1.7.1 递归函数剖析 ¶
1.7.2 互递归 ¶
1.7.3 递归函数中的打印 ¶
1.7.4 树递归 ¶
1.7.5 示例:分割数 ¶
求正整数 n 的分割数,最大部分为 m,即 n 可以分割为不大于 m 的正整数的和,并且按递增顺序排列。例如,使用 4 作为最大数对 6 进行分割的方式有 9 种。
1. 6 = 2 + 4
2. 6 = 1 + 1 + 4
3. 6 = 3 + 3
4. 6 = 1 + 2 + 3
5. 6 = 1 + 1 + 1 + 3
6. 6 = 2 + 2 + 2
7. 6 = 1 + 1 + 2 + 2
8. 6 = 1 + 1 + 1 + 1 + 2
9. 6 = 1 + 1 + 1 + 1 + 1 + 1
我们将定义一个名为 count_partitions(n, m) 的函数,该函数返回使用 m 作为最大部分对 n 进行分割的方式的数量。这个函数有一个使用树递归的简单的解法,它基于以下的观察结果:
使用最大数为 m 的整数分割 n 的方式的数量等于
- 使用最大数为 m 的整数分割 n-m 的方式的数量,加上
- 使用最大数为 m-1 的整数分割 n 的方式的数量
要理解为什么上面的方法是正确的,我们可以将 n 的所有分割方式分为两组:至少包含一个 m 的和不包含 m 的。此外,第一组中的每次分割都是对 n-m 的分割,然后在最后加上 m。在上面的实例中,前两种拆分包含 4,而其余的不包含。
因此,我们可以递归地将使用最大数为 m 的整数分割 n 的问题转化为两个较简单的问题:① 使用最大数为 m 的整数分割更小的数字 n-m,以及 ② 使用最大数为 m-1 的整数分割 n。
为了实现它,我们需要指定以下的基线情况:
- 整数 0 只有一种分割方式
- 负整数 n 无法分割,即 0 种方式
- 任何大于 0 的正整数 n 使用 0 或更小的部分进行分割的方式数量为 0
示例:
>>> def count_partitions(n, m):
"""计算使用最大数 m 的整数分割 n 的方式的数量"""
if n == 0:
return 1
elif n < 0:
return 0
elif m == 0:
return 0
else:
return count_partitions(n-m, m) + count_partitions(n, m-1)
>>> count_partitions(6, 4)
9
>>> count_partitions(5, 5)
7
>>> count_partitions(10, 10)
42
>>> count_partitions(15, 15)
176
>>> count_partitions(20, 20)
627
2 使用数据构建抽象 ¶
2.1 引言 ¶
2.1.1 原始数据类型 ¶
2.2 数据抽象 ¶
2.2.1 示例:有理数 ¶
2.2.2 对 ¶
2.2.3 抽象屏障 ¶
抽象屏障(Abstraction Barrier)是编程中一个非常重要的概念,帮助我们管理复杂性,确保代码模块之间的独立性。简单来说,它规定了如何使用一个模块,以及不需要知道模块内部的具体实现细节。我们只需知道模块提供了哪些功能,而不关心它是如何实现这些功能的。
1. 咖啡机的例子
- 抽象屏障: 你只需要按下“开始”按钮,等待一会儿,咖啡就会自动出来。
- 内部实现(被隐藏
) : 你不需要知道水如何被加热、咖啡豆如何被研磨,或者水是如何流过咖啡粉的。
在编程中的类比:
假设我们有一个 CoffeeMachine 类,你只需要调用 make_coffee() 方法,而不需要知道这个方法内部是如何工作的。
class CoffeeMachine:
def make_coffee(self):
self._heat_water()
self._grind_beans()
self._brew()
print("Your coffee is ready!")
def _heat_water(self):
print("Heating water...")
def _grind_beans(self):
print("Grinding coffee beans...")
def _brew(self):
print("Brewing the coffee...")
# 使用者只需要调用这个接口
machine = CoffeeMachine()
machine.make_coffee()
抽象屏障: 你只调用 make_coffee(),并不需要了解 _heat_water、_grind_beans 这些细节。
当程序中有一部分本可以使用更高级别函数但却使用了低级函数时,就会违反抽象屏障。例如,计算有理数平方的函数最好用 mul_rational 实现,它不对有理数的实现做任何假设。
直接引用分子和分母会违反一个抽象屏障。
>>> def square_rational_violating_once(x):
return rational(numer(x) * numer(x), denom(x) * denom(x))
假设有理数会表示为双元素列表将违反两个抽象屏障。
2.2.4 数据的属性 ¶
2.3 序列 ¶
2.3.1 列表 ¶
s.pop (i): 删除下标为 i 的元素并返回 s[i], 如果无参数则删除并返回末尾元素s.remove(x): 删除列表中第一个值为 x 的元素,无返回值s.extend(iterable): 将iterable(可迭代对象)的元素逐个添加到列表 s 末尾。直接修改 s,无返回值s.append(i): 在列表 s 末尾添加一个元素 i ,并直接修改 ss.insert(index,value): 在列表 s 的指定位置 index 处插入元素 value ,并直接修改 s, 若 index 超过列表长度则添加到最后s.remove(value): 删除列表中第一个匹配value的元素。sorted(iterable, key=None, reverse=False): 默认升序排列,key 是指定排序规则的函数,不修改原列表而是返回一个新的列表s.sort(key=None, reverse=False): 直接修改原列表而不返回新列表
一道错题:
>>> s = [3,4,5]
>>> s.extend([s.append(9), s.append(10)])
>>> s
[3, 4, 5, 9, 10, None, None]
>>>

2.3.2 序列遍历 ¶
2.3.3 序列处理 ¶
2.3.4 序列抽象 ¶
2.3.5 字符串 ¶
2.3.6 树 ¶
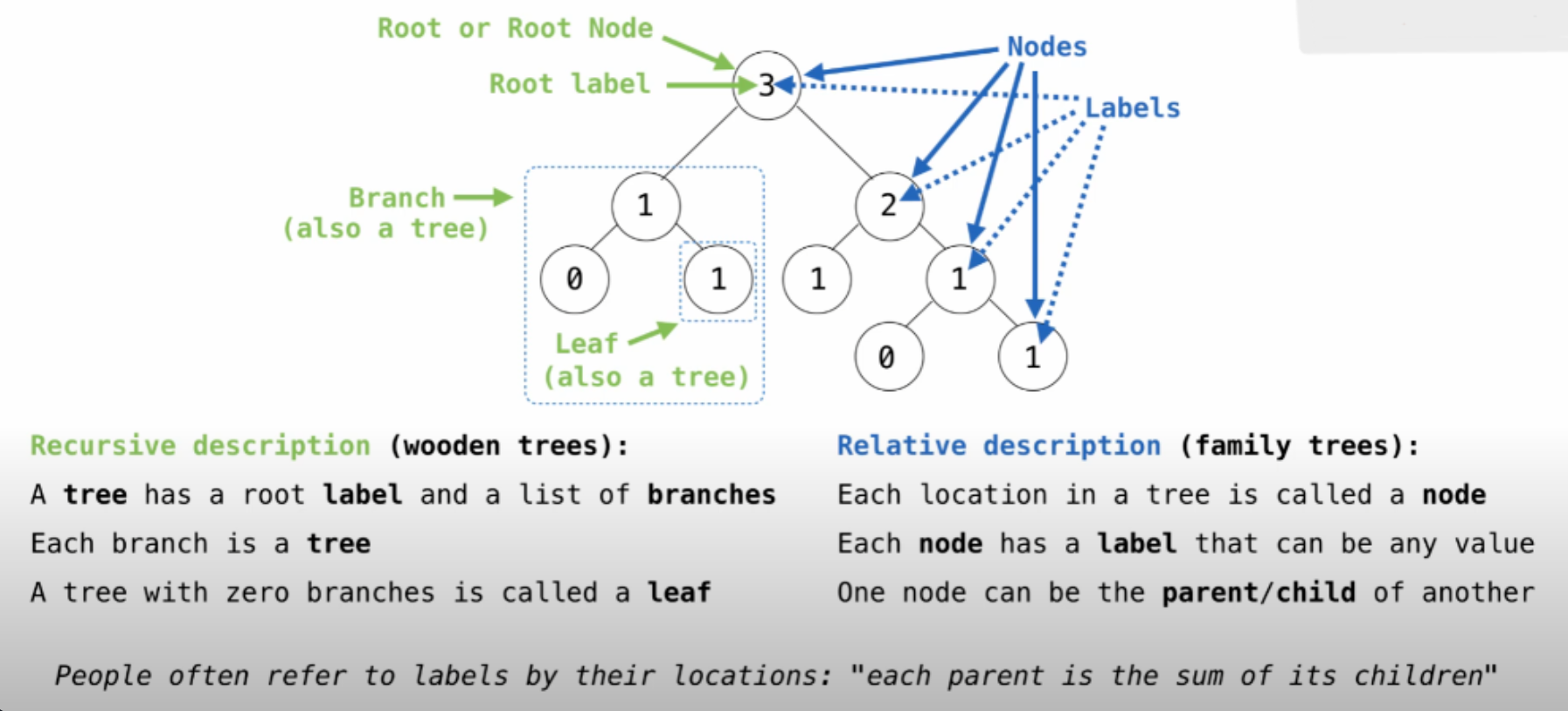
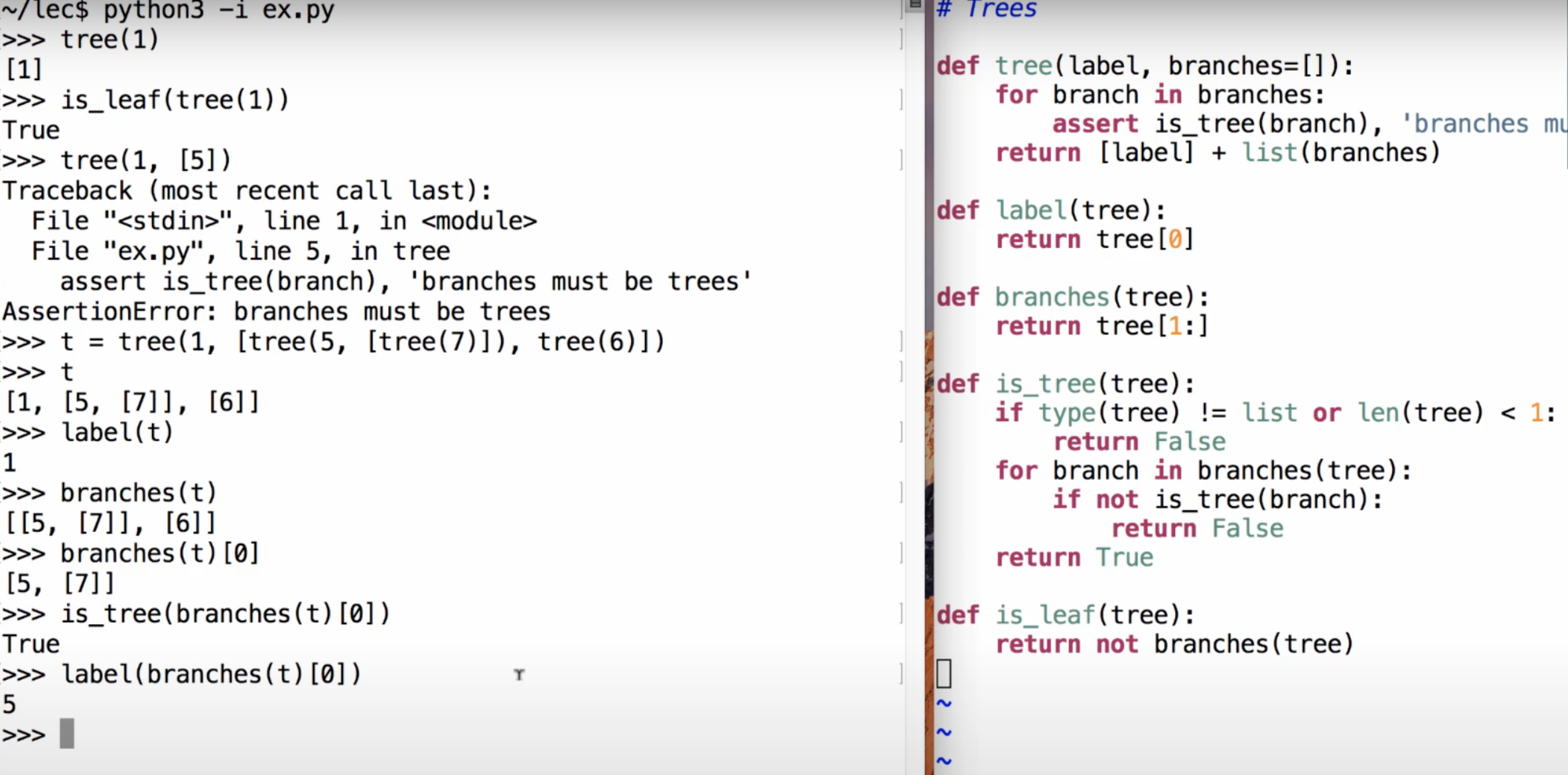
图片中的代码:
def tree(label,branches=[]):
for branch in branches:
assert is_tree(branch), 'branches must be tree'
return [label] + list(branches)
def label(tree):
return tree[0]
def branches(tree):
return tree[1:]
def is_leaf(tree):
if(not branches(tree)):
return True
else:
return False
def is_tree(tree):
if(type(tree) != list or len(tree) < 1):
return False
else:
for branch in branches(tree):
if(not is_tree(branch)):
return False
return True
- 分割树:
def partition_tree(n,m):
if(n == 0):
return tree(True)
elif(n < 0 or m == 0):
return tree(False)
else:
left = partition_tree(n - m, m)
right = partition_tree(n, m - 1)
return tree(m, [left,right])
- 斐波那契树:
>>> def fib_tree(n):
if n == 0 or n == 1:
return tree(n)
else:
left, right = fib_tree(n-2), fib_tree(n-1)
fib_n = label(left) + label(right)
return tree(fib_n, [left, right])
>>> fib_tree(5)
[5, [2, [1], [1, [0], [1]]], [3, [1, [0], [1]], [2, [1], [1, [0], [1]]]]]
>>> def count_leaves(tree):
if is_leaf(tree):
return 1
else:
branch_counts = [count_leaves(b) for b in branches(tree)]
return sum(branch_counts)
>>> count_leaves(fib_tree(5))
8
2.3.7 链表 ¶
2.4 可变数据 ¶
2.4.1 对象隐喻 ¶
2.4.2 序列对象 ¶
像数字这样的基本数据类型的实例是不可变(immutable)的。它们所代表的值,在程序运行期间是不可以更改的。另一方面,列表就是可变的(mutable
>>> chinese = ['coin', 'string', 'myriad'] # 一组字符串列表
>>> suits = chinese # 为同一个列表指定了两个不同的变量名
>>> suits.pop() # 从列表中移除并返回最后一个元素
'myriad'
>>> suits.remove('string') # 从列表中移除第一个与参数相同的元素
>>> suits.append('cup') # 在列表最后插入一个元素
>>> suits.extend(['sword', 'club']) # 将另外一个列表中的所有元素添加到当前列表最后
>>> suits[2] = 'spade' # 替换某个元素
>>> suits
['coin', 'cup', 'spade', 'club']
>>> suits[0:2] = ['heart', 'diamond'] # 替换一组数据
>>> suits
['heart', 'diamond', 'spade', 'club']
>>> chinese # 这个变量名与 "suits" 指向的是同一个列表对象
['heart', 'diamond', 'spade', 'club']
- 数据共享和身份(Sharing and Identity)。 正是由于我们没有在操作数据时创建新的列表,而是直接操作的源数据,这就导致变量 chinese 也被改变了,因为它和变量 suits 绑定到时同一个列表!
我们可以利用列表的构造器函数 list 来对一个列表进行复制。复制完成后,两个列表数据的改动不会再影响彼此,除非二者共享了同一份数据。
>>> nest = list(suits) # 复制一个与 suits 相同的列表,并命名为 nest
>>> nest[0] = suits # 创建一个嵌套列表,列表第一项是另一个列表
根据当前的运行环境,改动变量 suits 所对应的列表数据会影响到 nest 列表的第一个元素,也就是我们上面刚刚创建的嵌套列表,而 nest 中的其它元素不受影响:
>>> suits.insert(2, 'Joker') # 在下标为 2 的位置插入一条新元素,其余元素相应向后移动
>>> nest
[['heart', 'diamond', 'Joker', 'spade', 'club'], 'diamond', 'spade', 'club']
- 可以用
is和is not来区分两个变量是否指向同一个对象
元组: Python 内置类型 tuple 的实例对象,其是不可变序列。我们可以将不同数据用逗号分隔,用这种字面量的方式即可以创建一个元组。括号并不是必须的,但是一般都会加上。元组中可以放置任意对象。
>>> 1, 2 + 3
(1, 5)
>>> ("the", 1, ("and", "only"))
('the', 1, ('and', 'only'))
>>> type( (10, 20) )
<class 'tuple'>
>>> () # 0 elements
()
>>> (10,) # 1 element
(10,)
- 和列表相同,元组有确定的长度,并支持元素索引。元组还有一些与列表相同的方法,比如
count和index
>>> code = ("up", "up", "down", "down") + ("left", "right") * 2
>>> len(code)
8
>>> code[3]
'down'
>>> code.count("down")
2
>>> code.index("left")
4
- 尽管元组不可变,但是若元组中的元素本身是可变数据,那我们也是可以对该元素进行操作的

2.4.3 字典 ¶
- 字典是无序的,多次运行程序,字典输出的顺序可能会有所变化
字典的一些操作
key不能是可变数据也不能包含可变数据,比如元组可以做key但是列表不行- 一个
key只能对应一个value
2.4.4 局部状态 ¶
>>> def make_withdraw(balance):
"""返回一个每次调用都会减少 balance 的 withdraw 函数"""
def withdraw(amount):
nonlocal balance # 声明 balance 是非局部的
if amount > balance:
return '余额不足'
balance = balance - amount # 重新绑定
return balance
return withdraw
>>> withdraw(25)
75
>>> withdraw(25)
50
>>> withdraw(60)
'余额不足'
>>> withdraw(15)
35
- 当 balance 属性为声明为 nonlocal 后,每当它的值发生更改时,相应的变化都会同步更新到
balance属性第一次被声明的位置 - 第二次调用 withdraw 像往常一样创建了第二个局部帧。并且,这两个 withdraw 帧都具有相同的父级帧。也就是说,它们都集成了 make_withdraw 的运行环境,而变量 balance 就是在该环境中定义和声明的。因此,它们都可以访问到 balance 变量的绑定关系。调用 withdraw 会改变当前运行环境,并且影响到下一次调用 withdraw 的结果。nonlocal 声明语句允许 withdraw 更改 make_withdraw 运行帧中的变量。
- 另外,如果用 python tutor 实践会发现这个错误发生在第 5 行执行之前,这意味着 Python 在执行第 3 行之前,就以某种方式考虑了第 5 行的代码。
global和nonlocal的区别总结 (from ChatGPT4o)
| 特性 | global | nonlocal |
|---|---|---|
| 作用范围 | 影响全局作用域中的变量 | 影响外层函数的局部作用域中的变量 |
| 适用场景 | 在函数内修改全局变量 | 在嵌套函数内修改外层函数的局部变量 |
| 常见错误 | 忘记声明 global,导致修改的是局部变量 | 忘记声明 nonlocal,导致修改的是嵌套函数内的局部变量 |
| 多层嵌套 | 可以直接访问模块级全局变量 | 只能作用于最近一层的封闭作用域中的变量 |
| 不能做的事 | 无法修改局部变量,除非显式声明 global | 无法作用于全局变量,只能修改封闭作用域中的变 |
2.4.5 非局部 Non-local 赋值的好处 ¶
def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
return 'Insufficient funds'
balance = balance - amount
return balance
return withdraw
wd = make_withdraw(20)
wd2 = make_withdraw(7)
wd2(6)
wd(8)
- 未来对 wd 的调用不受 wd2 的 balance 变化的影响
2.4.6 非局部 Non-local 赋值的代价 ¶
def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
return 'Insufficient funds'
balance = balance - amount
return balance
return withdraw
wd = make_withdraw(12)
wd2 = wd
wd2(1)
wd(1)
- 在这种情况下,调用 wd2 命名的函数确实改变了 wd 命名的函数的值,因为两个名称都引用同一个函数。
2.4.7 列表和字典实现 ¶
2.4.8 调度字典(Dispatch Dictionaries)¶
2.4.9 约束传递 (Propagating Constraints) ¶
2.5 面向对象编程 ¶
2.5.1 对象和类 ¶
- 实例属性 : 对于特定对象,其有特定值的属性
, (而不是类的所有对象)称为实例属性
>>> class Account:
def __init__(self, account_holder):
self.balance = 0 #实例属性1
self.holder = account_holder #实例属性2
2.5.2 类的定义 ¶
>>> class Account:
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
Account的__init__方法有两个形式参数。第一个self绑定到新创建的Account对象。第二个参数account_holder绑定到调用类进行实例化时传递给类的参数。
- 每一个
account有自己独立的余额属性
- 赋值将对象绑定到新名称不会创建新的对象
>>> class Account:
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
def deposit(self, amount):
self.balance = self.balance + amount
return self.balance
def withdraw(self, amount):
if amount > self.balance:
return 'Insufficient funds'
self.balance = self.balance - amount
return self.balance
2.5.3 消息传递和点表达式 ¶
- 在对象上调用方法时,对象作为第一个参数隐式传递给该方法。即对象绑定到参数
self
方法和函数在交互解释器下的差异:
- 命名约定:
- 类名通常使用 CapWords 约定(也称为 CamelCase,因为名称中间的大写字母看起来像驼峰)编写。示例如下
EmployeeRecordHttpRequestHandlerDatabaseConnection
- 方法名称遵循使用下划线分隔的小写单词命名函数的标准约定。
- 类名通常使用 CapWords 约定(也称为 CamelCase,因为名称中间的大写字母看起来像驼峰)编写。示例如下
2.5.4 类属性 ¶
- 类属性与类本身相关联,不与类的任何单个实例相关联
- 类属性的赋值会改变所有类的实例的类属性值
>>> class Account:
interest = 0.02 # 类属性
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
# 在这里定义更多的方法
>>> spock_account = Account('Spock')
>>> kirk_account = Account('Kirk')
>>> spock_account.interest
0.02
>>> kirk_account.interest
0.02
>>> Account.interest = 0.04 #类属性的赋值会改变类的所有实例的属性值
>>> spock_account.interest
0.04
>>> kirk_account.interest
0.04
类属性和实例属性很有可能会同名,所以计算点表达式时遵循以下规则:
- 点表达式左侧的
<expression>,生成点表达式的对象。 <name>与该对象的实例属性匹配;如果存在具有该名称的属性,则返回属性值。- 如果实例属性中没有
<name>,则在类中查找<name>,生成类属性。 - 除非它是函数,否则返回属性值。如果是函数,则返回该名称绑定的方法。
>>> kirk_account.interest = 0.08
>>> kirk_account.interest
0.08
>>> spock_account.interest
0.04
>>> Account.interest = 0.05 # 改变类属性
>>> spock_account.interest # 实例属性发生变化(该实例中没有和类属性同名称的实例属性)
0.05
>>> kirk_account.interest # 如果实例中存在和类属性同名的实例属性,则改变类属性,不会影响实例属性
0.08
2.5.5 继承 ¶
>>> class CheckingAccount(Account):
"""从账号取钱会扣出手续费的账号"""
withdraw_charge = 1
interest = 0.01
def withdraw(self, amount):
return Account.withdraw(self, amount + self.withdraw_charge)
>>> ch = CheckingAccount('Spock')
>>> ch.interest # Lower interest rate for checking accounts
0.01
>>> ch.deposit(20) # Deposits are the same
20
>>> ch.withdraw(5) # withdrawals decrease balance by an extra charge
14
- checkingAccount 是 account 的子类,子类继承其父类的属性,也可以重写某些属性,在子类中未指定的任何内容都会被自动假定为与父类的行为一样
2.5.6 使用继承 ¶
上述例子的完整实现:
>>> class Account:
"""一个余额非零的账户。"""
interest = 0.02
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
def deposit(self, amount):
"""存入账户 amount,并返回变化后的余额"""
self.balance = self.balance + amount
return self.balance
def withdraw(self, amount):
"""从账号中取出 amount,并返回变化后的余额"""
if amount > self.balance:
return 'Insufficient funds'
self.balance = self.balance - amount
return self.balance
>>> class CheckingAccount(Account):
"""从账号取钱会扣出手续费的账号"""
withdraw_charge = 1
interest = 0.01
def withdraw(self, amount):
return Account.withdraw(self, amount + self.withdraw_charge)
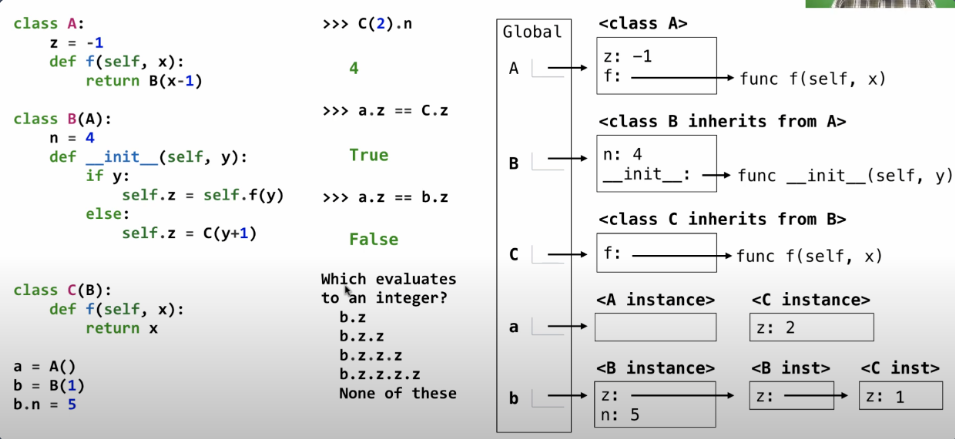
在类中查找名称:
- 如果它命名在指定类中的属性则返回属性值
- 否则在该类的父类中查找该名称的属性
- 接口定义了一组方法和属性,确保不同的类(
Account和CheckingAccount)都具有相同的行为。 - 这样,无论是哪种账户类型,我们都可以放心地使用
deposit、withdraw和balance,而不用关心具体的账户类别。
这个挺绕的
2.5.7 多继承 ¶
>>> class SavingsAccount(Account):
deposit_charge = 2
def deposit(self, amount):
return Account.deposit(self, amount - self.deposit_charge)
>>> class AsSeenOnTVAccount(CheckingAccount, SavingsAccount):
def __init__(self, account_holder):
self.holder = account_holder
self.balance = 1 # 赠送的 1 $!
>>> such_a_deal = AsSeenOnTVAccount("John")
>>> such_a_deal.balance
1
>>> such_a_deal.deposit(20) # 调用 SavingsAccount 的 deposit 方法,会产生 2 $的存储费用
19
>>> such_a_deal.withdraw(5) # 调用 CheckingAccount 的 withdraw 方法,产生 1 $的取款费用。
13
- 继承结构:
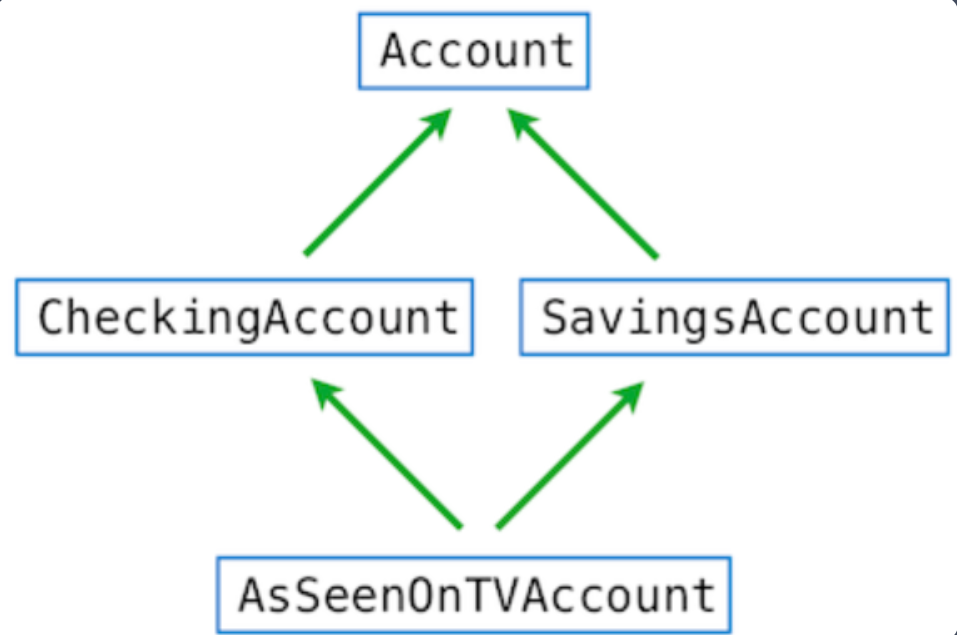
遵循从左到右,从下到上的检索规则
2.5.8 对象的作用 ¶
2.7 对象抽象 ¶
2.7.1 字符串转换 ¶
repr(object) -> string
Return the canonical string representation of the object.
For most object types, eval(repr(object)) == object
返回对象的标准字符串表示。
对于大多数对象类型,
eval(repr(object)) == object。
>>> repr(min)
'<built-in function min>'
>>> from datetime import date
>>> tues = date(2011, 9, 12)
>>> repr(tues)
'datetime.date(2011, 9, 12)'
>>> str(tues)
'2011-09-12'
repr函数无法正确地应用到所有的数据类型- 解决方案:使用 object 系统 --
repr总是再其参数值上调用一个名为__repr__的方法
class Ratio:
def __init__(self, n, d):
self.numer = n
self.denom = d
def __repr__(self):
return 'Ratio({0}, {1})'.format(self.numer, self.denom)
def __str__(self):
return '{0}/{1}'.format(self.numer,self.denom)
- 当你直接输入对象时,Python 会自动调用该对象的
__repr__方法来返回对象的字符串表示。 - 在交互式环境中,Python 会自动 调用对象的
__repr__()方法 来获得该对象的字符串表示并显示在屏幕上。 - 输出
Ratio(1, 2)没有引号包围,因为它是对象的 显示形式,而不是字符串本身。Python 会将__repr__()方法的返回值直接打印出来。 - 当你使用
print()函数时,Python 会调用该对象的__str__方法来获取对象的字符串表示。 format: 格式化输出,{} 内的数字表示索引
2.7.2 专用方法 ¶
>>> bool(Account('Jack'))
False
>>> if not Account('Jack'):
print('Jack has nothing')
Jack has nothing
- 如果序列没有提供
__bool__方法,那么 Python 会使用序列的长度来确定其真假值。空的序列是假值,而非空序列是真值。
>>> def make_adder(n):
def adder(k):
return n + k
return adder
>>> add_three = make_adder(3)
>>> add_three(4)
7
- 下面是等效的
Adder类
>>> class Adder(object):
def __init__(self, n):
self.n = n
def __call__(self, k):
return self.n + k
>>> add_three_obj = Adder(3)
>>> add_three_obj(4)
7
2.7.3 多重表示 ¶
以复数的相乘和相加为例:
>>> class Number:
def __add__(self, other):
return self.add(other)
def __mul__(self, other):
return self.mul(other)
>>> class Complex(Number): # 继承Number类
def add(self, other):
return ComplexRI(self.real + other.real, self.imag + other.imag)
def mul(self, other):
magnitude = self.magnitude * other.magnitude
return ComplexMA(magnitude, self.angle + other.angle)
>>> from math import atan2
>>> class ComplexRI(Complex): # 继承Complex类
def __init__(self, real, imag):
self.real = real
self.imag = imag
@property
def magnitude(self):
return (self.real ** 2 + self.imag ** 2) ** 0.5
@property
def angle(self):
return atan2(self.imag, self.real)
def __repr__(self):
return 'ComplexRI({0:g}, {1:g})'.format(self.real, self.imag)
>>> ri = ComplexRI(5, 12)
>>> ri.real
5
>>> ri.magnitude
13.0
>>> ri.real = 9
>>> ri.real
9
>>> ri.magnitude
15.0
>>> from math import sin, cos, pi
>>> class ComplexMA(Complex):
def __init__(self, magnitude, angle):
self.magnitude = magnitude
self.angle = angle
@property
def real(self):
return self.magnitude * cos(self.angle)
@property
def imag(self):
return self.magnitude * sin(self.angle)
def __repr__(self):
return 'ComplexMA({0:g}, {1:g} * pi)'.format(self.magnitude, self.angle/pi)
>>> ma = ComplexMA(2, pi/2)
>>> ma.imag
2.0
>>> ma.angle = pi
>>> ma.real
-2.0
>>> from math import pi
>>> ComplexRI(1, 2) + ComplexMA(2, pi/2)
ComplexRI(1, 4)
>>> ComplexRI(0, 1) * ComplexRI(0, 1)
ComplexMA(1, 1 * pi)
2.7.4 泛型函数 ¶
2.8 效率 ¶
2.8.1 测量效率 ¶
>>> def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 2) + fib(n - 1)
>>> fib(5)
5
- 对调用次数计数:
>>> def count(f):
def counted(n):
counted.call_count += 1
return f(n)
counted.call_count = 0
return counted
>>> fib = count(fib)
>>> fib(19)
4181
>>> fib.call_count
10946
- python 解释器会回收不影响未来计算的内存,树递归函数所需的空间将与数的最大深度成比例
- 计数最大调用帧:
>>> def count_frames(f):
def counted(n):
counted.open_count += 1 # 开辟帧
counted.max_count = max(counted.max_count, counted.open_count)
result = f(n)
counted.open_count -= 1 # 计算完了释放帧
return result
counted.open_count = 0
counted.max_count = 0
return counted
>>> fib = count_frames(fib)
>>> fib(19)
4181
>>> fib.open_count
0
>>> fib.max_count
19
>>> fib(24)
46368
>>> fib.max_count
24
2.8.2 记忆化 ¶
>>> def memo(f):
cache = {}
def memorized(n):
if n not in cache:
cache[n] = f(n)
return cache[n]
return memorized
>>> counted_fib = count(fib)
>>> fib =memo(count_fib)
>>> fib(19)
4181
>>> counted_fib.call_count
20
>>> fib(34)
5702887
>>> counted_fib.call_count
35
- 应用 memo 后新的计算模式
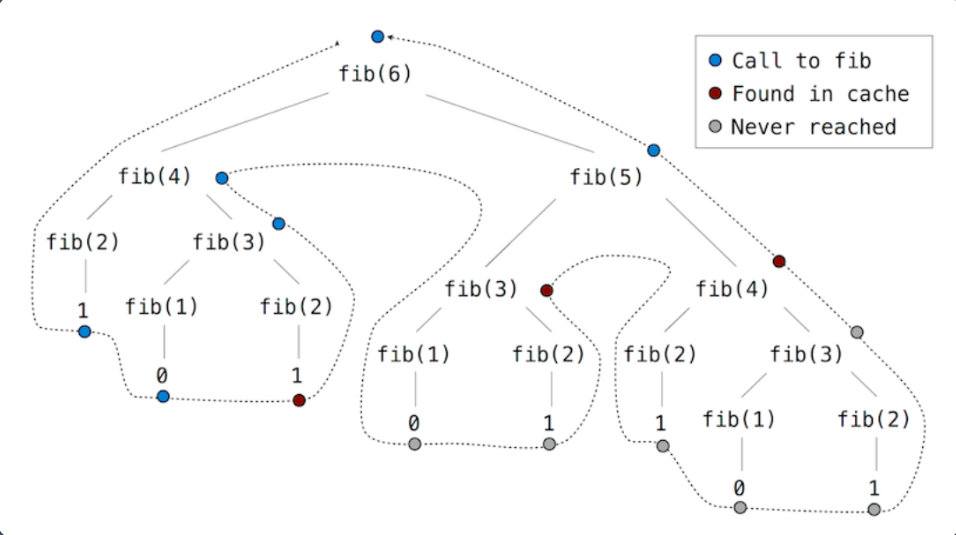
- 对于每个唯一的输入 , fib 只被调用一次
2.8.3 增长阶数 ¶
2.8.4 示例:指数运算 ¶
2.8.5 增长类别 ¶
Data example¶


min(s, key=abs) :根据每个元素的 绝对值 找出 s 中的最小元素。如果有多个元素的绝对值相同,它会返回第一个最小的元素。
Link List¶
class Link:
"""A linked list.
>>> s = Link(1)
>>> s.first
1
>>> s.rest is Link.empty
True
>>> s = Link(2, Link(3, Link(4)))
>>> s.first = 5
>>> s.rest.first = 6
>>> s.rest.rest = Link.empty
>>> s # Displays the contents of repr(s)
Link(5, Link(6))
>>> s.rest = Link(7, Link(Link(8, Link(9))))
>>> s
Link(5, Link(7, Link(Link(8, Link(9)))))
>>> print(s) # Prints str(s)
<5 7 <8 9>>
"""
empty = ()
def __init__(self, first, rest=empty):
assert rest is Link.empty or isinstance(rest, Link)
self.first = first
self.rest = rest
def __repr__(self):
if self.rest is not Link.empty:
rest_repr = ', ' + repr(self.rest)
else:
rest_repr = ''
return 'Link(' + repr(self.first) + rest_repr + ')'
def __str__(self):
string = '<'
while self.rest is not Link.empty:
string += str(self.first) + ' '
self = self.rest
return string + str(self.first) + '>'
def range_Link(start, end):
"""
>>> range_Link(3,6)
Link(3, Link(4, Link(5)))
"""
# end -= 1
# res = Link.empty
# while(end >= start):
# res = Link(end, res)
# end -= 1
# return res
if(start >= end):
return Link.empty
else:
return Link(start,range_Link(start + 1, end))
def map_Link(f, s):
if(s == Link.empty):
return s
else:
return Link(f(s.first), map_Link(s.rest))
def filter_Link(f, s):
if(s == Link.empty):
return s
elif(f(s)):
return Link(s.first, filter_Link(f, s.rest))
elif(not f(s)):
return Link(filter_Link(f,s.rest))
3 计算机程序的解释 ¶
3.1 引言 ¶
- 本章将介绍 Scheme 编程语言
- 语法介绍
3.2 函数式编程 ¶
3.2.1 表达式 ¶
3.2.2 定义 ¶
- 运算符前置
scm> (* 3 (+ 4 2))
18
scm> (+ 1 2)
3
scm> (- 10 (/ 6 2))
7
scm> (modulo 35 4)
3
scm> (even? (quotient 45 2))
#t
- Define:
- define can alse create a procedure!
scm> (define (double x) (* x 2))
double
scm> (double 3)
6
scm> (define (add-then-mul x y z)
(* (+ x y) z))
scm> (add-then-mul 3 4 5)
35
- if exp:
`
scm> (define x 3)
x
scm> (if (> (- x 3) 0) (/ 1 (- x 3)) (+ x 2))
5
scm> (if (= x 3) (print x))
3
- Cond: scheme 语言不支持 elif
``
scm> (define x 5)
x
scm> (cond ((= (modulo x 3) 0) x)
((= (modulo x 3) 1) (- x 1))
((= (modulo x 3) 2) (+ x 1)))
6
- lambda:
scm> (lambda (x y) (+ x y)) ; Returns a lambda procedure, but doesn't assign it to a name
(lambda (x y) (+ x y))
scm> ((lambda (x y) (+ x y)) 3 4) ; Create and call a lambda procedure in one line
7
3.2.3 复合类型 ¶
- scheme 语言中,pair 通过 cons 创建,而元素可以通过 car 和 cdr 访问
- scheme 中的列表就像 Python 中的
Link类
(cons 1
(cons 2
(cons 3
(cons 4 nil))))
(1 2 3 4)
(list 1 2 3 4)
(1 2 3 4)
(define one-through-four (list 1 2 3 4))
(car one-through-four)
1
(cdr one-through-four)
(2 3 4)
(car (cdr one-through-four))
2
(cons 10 one-through-four)
(10 1 2 3 4)
(cons 5 one-through-four)
(5 1 2 3 4)
- 使用
null?判断一个列表是否为空
(define (length items) ;; 测量列表的长度
(if (null? items)
0
(+ 1 (length (cdr items)))))
(define (getitem items n) ;; 获取列表索引为 n 的元素
(if (= n 0)
(car items)
(getitem (cdr items) (- n 1))))
(define squares (list 1 4 9 16 25))
(length squares)
5
(getitem squares 3)
16
Scheme Lists & Quotation
niland()are the same thing: the empty list.(cons first rest)constructs a linked list withfirstas its first element. andrestas the rest of the list, which should always be a list.(car s)returns the first element of the lists.(cdr s)returns the rest of the lists.(list ...)takes n arguments and returns a list of length n with those arguments as elements.(append ...)takes n lists as arguments and returns a list of all of the elements of those lists.(draw s)draws the linked list structure of a lists. It only works on code.cs61a.org/scheme. Try it now with something like(draw (cons 1 nil)).
3.2.4 符号数据 ¶
- scheme 语言能够处理任意符号作为数据
(define a 1)
(define b 2)
(list a b)
(1 2)
(list 'a 'b)
(a b)
(list 'a b)
(a 2)
(list 'define 'list)
(define list)
(car '(a b c))
a
(cdr '(a b c))
(b c)
3.3 异常 ¶
- 异常是一个对象实例,其类直接或间接继承自
BaseException类。 - assert 语句抛出
AssertionError的异常。 - 通常可以用
raise语句抛出任何异常实例
>>> raise Exception(' An error occurred')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
Exception: an error occurred
- 抛出异常后,当前代码块中的后续语句将不会执行,除非异常被处理
- 上述示例中,文件名
<stdin>表示该异常是由用户在交互会话中引发的,而不是来自文件中的代码 - 处理异常-- try 语句
<try suite>立即执行。只有在<try suite>过程中发生异常时,except 字句的内容才会执行- 如果
<exception class>为AssertionError,那么AssertionError绑定到name( 不会在except suite外存在 ) ,<try suite>过程中引发的任何继承自AssertionError类的实例由随后的<except suite>处理。
>>> try:
x = 1 / 0:
except ZeroDivisionError as e:
print('handling a', type(e))
x = 0
handling a <class 'ZeroDivisionError'>
>>> x
0
>>> def invert(x):
result = 1/x # 抛出一个异常(ZeroDivisionError) 如果 x 为 0
print('Never printed if x is 0')
return result
>>> def invert_safe(x):
try:
return invert(x)
except ZeroDivisionError as e:
return str(e)
>>> invert_safe(2)
Never printed if x is 0
0.5
>>> invert_safe(0)
'division by zero'
3.3.1 异常对象 ¶
>>> class IterImproveError(Exception):
def __init__(self, last_guess):
self.last_guess = last_guess
>>> def improve(update, done, guess=1, max_updates=1000):
k = 0
try:
while not done(guess) and k < max_updates:
guess = update(guess)
k = k + 1
return guess
except ValueError:
raise IterImproveError(guess) # 抛出异常
>>> def find_zero(f, guess=1):
def done(x):
return f(x) == 0
try:
return improve(newton_update(f), done, guess)
except IterImproveError as e: # raise 抛出的异常被捕获
return e.last_guess # 采用自定义方法处理异常
>>> from math import sqrt
>>> find_zero(lambda x: 2*x*x + sqrt(x))
-0.030211203830201594
3.4 组合语言的解释器 ¶
3.4.1 基于 Scheme 语法的计算器 ¶
3.4.2 表达式树 ¶
想要编写一个 Scheme 计算器,我们需要定义一个嵌套对 Pair
嵌套列表:
>>> expr = Pair('+', Pair(Pair('*', Pair(3, Pair(4, nil))), Pair(5, nil)))
>>> print(expr)
(+ (* 3 4) 5)
>>> print(expr.second.first)
(* 3 4)
>>> expr.second.first.second.first
3
3.4.3 解析表达式 ¶
解析过程:
- 词法分析器将输入字符串划分为几个最小语法单元,比如名称和符号。
- 语法分析器根据这个标记序列构建一个表达式树。
我们使用的分词器token_line :
3.4.4 计算器语言求值 ¶
3.5 抽象语言的解释器 ¶
4 数据处理 ¶
4.1 引言 ¶
4.2 隐式序列 ¶
- 惰性计算:指任何延迟计算,直到需要该值的程序
4.2.1 迭代器 ¶
迭代器抽象的两个组件:
- 检索下一个元素
- 到达序列末尾并且没有剩余元素,则发出信号
>>> primes = [2, 3, 5, 7]
>>> type(primes)
<class 'list'>
>>> iterator = iter(primes)
>>> type(iterator)
<class 'list-iterator'>
>>> next(iterator)
2
>>> next(iterator)
3
>>> next(iterator)
5
>>> next(iterator)
7
>>> next(iterator)
Traceback (most recent call las):
File "<stdin>", line 1, in <module>
StopIteration
>>> try:
next(iterator)
except StopIteration:
print('No more values')
No more values
>>> r = range(3, 13)
>>> s = iter(r) # r 的第一个迭代器
>>> next(s)
3
>>> next(s)
4
>>> t = iter(r) # r 的第二个迭代器
>>> next(t)
3
>>> next(t)
4
>>> u = t # u 绑定到 r 的第二个迭代器
>>> next(u)
5
>>> next(u)
6
- 在迭代器上调用
iter将返回该迭代器,而不是其副本。 Python 中包含此行为,以便程序员可以对某个值调用iter来获取迭代器,而不必担心它是迭代器还是容器。
>>> v = iter(t) # v 绑定到 r 的第二个迭代器
>>> next(v) # u, v, t 都为 r 的第二个迭代器
8
>>> next(u)
9
>>> next(t)
10
- 每次调用 iter(s) 都会创建一个新的迭代器
s = [1, 2, 3]
next(iter(s)) # 创建一个新迭代器,返回第一个元素 1
next(iter(s)) # 又创建一个新迭代器,返回第一个元素 1
next(iter(s)) # 再创建一个新迭代器,返回第一个元素 1
4.2.2 可迭代性 ¶
- 可以传递给
iter的对象都是可迭代值(itreble value) - 包括:
- 序列值:字符串,元组
- 容器:集合,字典
- 迭代器本身
- 字典在生成迭代器时也必须定义其内容的顺序
- 如果字典由于添加或删除键导致结构发生变化,则迭代器失效
>>> d = {'one': 1, 'two': 2, 'three': 3}
>>> d
{'one': 1, 'three': 3, 'two': 2}
>>> k = iter(d)
>>> next(k)
'one'
>>> next(k)
'three'
>>> v = iter(d.values())
>>> next(v)
1
>>> next(v)
3
4.2.3 内置迭代器 ¶
map
>>> def double_and_print(x):
print('***', x, '=>', 2*x, '***')
return 2*x
>>> s = range(3, 7)
>>> doubled = map(double_and_print, s) # double_and_print 未被调用
>>> next(doubled) # double_and_print 调用一次
*** 3 => 6 ***
6
>>> next(doubled) # double_and_print 再次调用
*** 4 => 8 ***
8
>>> list(doubled) # double_and_print 再次调用兩次
*** 5 => 10 *** # list() 会把剩余的值都计算出来并生成一个列表
*** 6 => 12 ***
[10, 12]
filterzipreversed- 以上三个函数也返回迭代器
4.2.4 For 语句 ¶
4.2.5 生成器和 Yield 语句 ¶
4.2.6 可迭代接口 ¶
4.2.7 使用 Yield 创建可迭代对象 ¶
4.2.8 迭代器接口 ¶
4.2.9 Streams¶
4.2.10 Python 流 ¶
4.3 声明式编程 ¶
4.4 Logic 语言编程 ¶
4.5 合一 ¶
4.6 分布式计算 ¶
4.7 分布式数据处理 ¶
4.8 并行计算 ¶
SQL¶
- 这里有简单教程 Lab 12 SQL | CS 自学社区